In this two for one episode recorded at HumanX, Ryan is first joined by Christine Yen, CEO of Honeycomb, to discuss how AI compresses the software development lifecycle, making observability about capturing the right telemetry. Then, Spiros Xanthos, founder and CEO of Resolve AI, shares with us how AI coding increases code volume but decreases human input, making production operations harder than ever.
Blog
-
Observability and human intuition in an AI world
In this two for one episode recorded at HumanX, Ryan is first joined by Christine Yen, CEO of Honeycomb, to discuss how AI compresses the software development lifecycle, making observability about capturing the right telemetry. Then, Spiros Xanthos, founder and CEO of Resolve AI, shares with us how AI coding increases code volume but decreases human intuition, making production operations harder than ever.
-
Pas de questions stupides : qu’est-ce que le cloud computing et pourquoi tout le monde le fait ?
Dans ce No Dumb Questions, Phoebe est rejointe par Josh Zhang, responsable technique de Stack Overflow pour l’équipe d’infrastructure, pour en savoir plus sur le cloud, le calcul et les centres de données.
-
Keine dummen Fragen: Was ist Cloud Computing und warum macht es jeder?
In diesem „Keine dummen Fragen“ wird Phoebe von Josh Zhang, dem technischen Leiter des Infrastrukturteams von Stack Overflow, begleitet, um mehr über die Cloud, Computer und Rechenzentren zu erfahren.
-
No Dumb Questions: What is cloud computing and why is everyone doing it?
In this No Dumb Questions, Phoebe is joined by Stack Overflow’s tech lead for the infrastructure team, Josh Zhang, to learn about the cloud, compute, and data centers.
-
No Dumb Questions: What is cloud computing and why is everyone doing it?
In this No Dumb Questions, Phoebe is joined by Stack Overflow’s tech lead for the infrastructure team, Josh Zhang, to learn about the cloud, compute, and data centers.
-
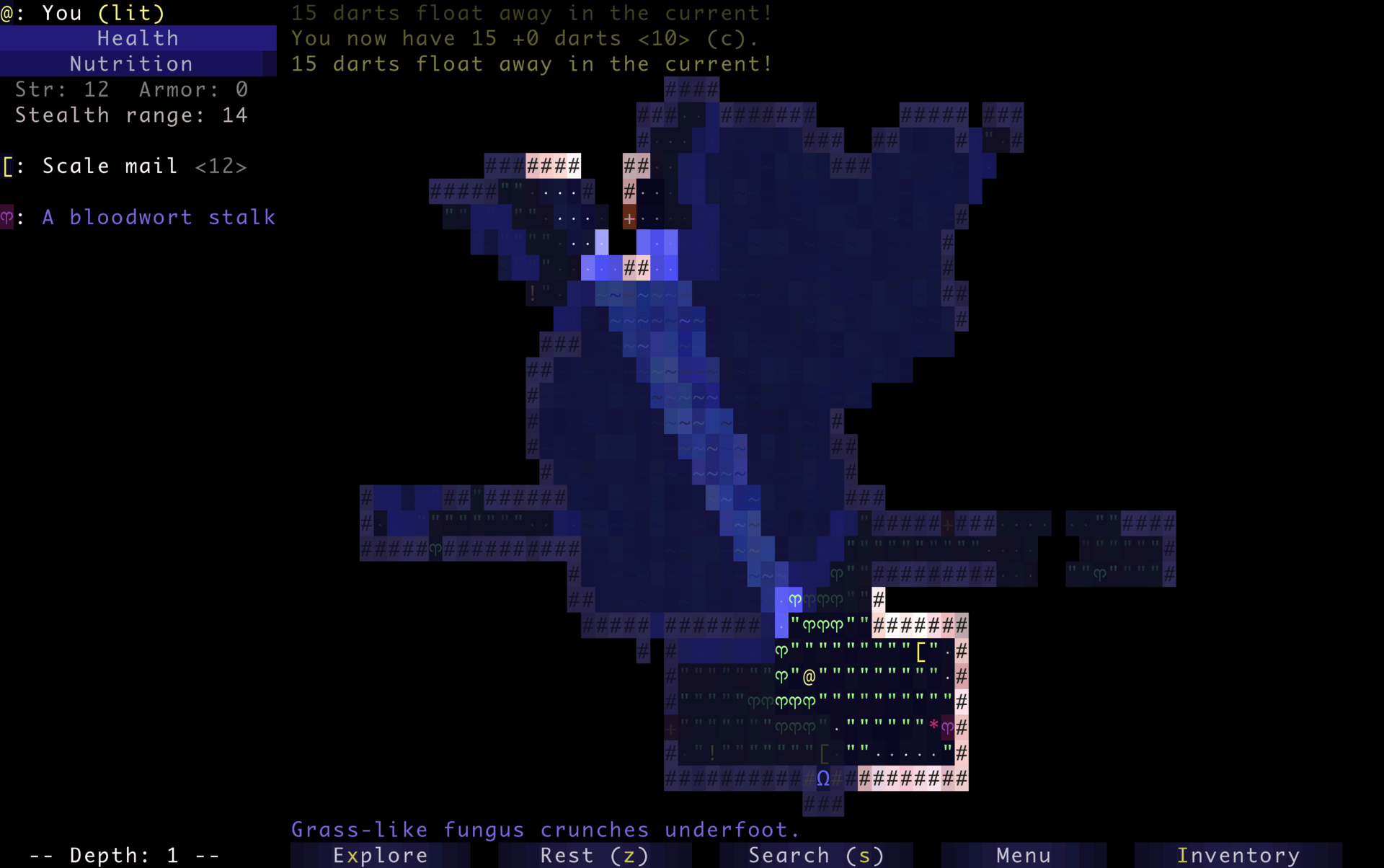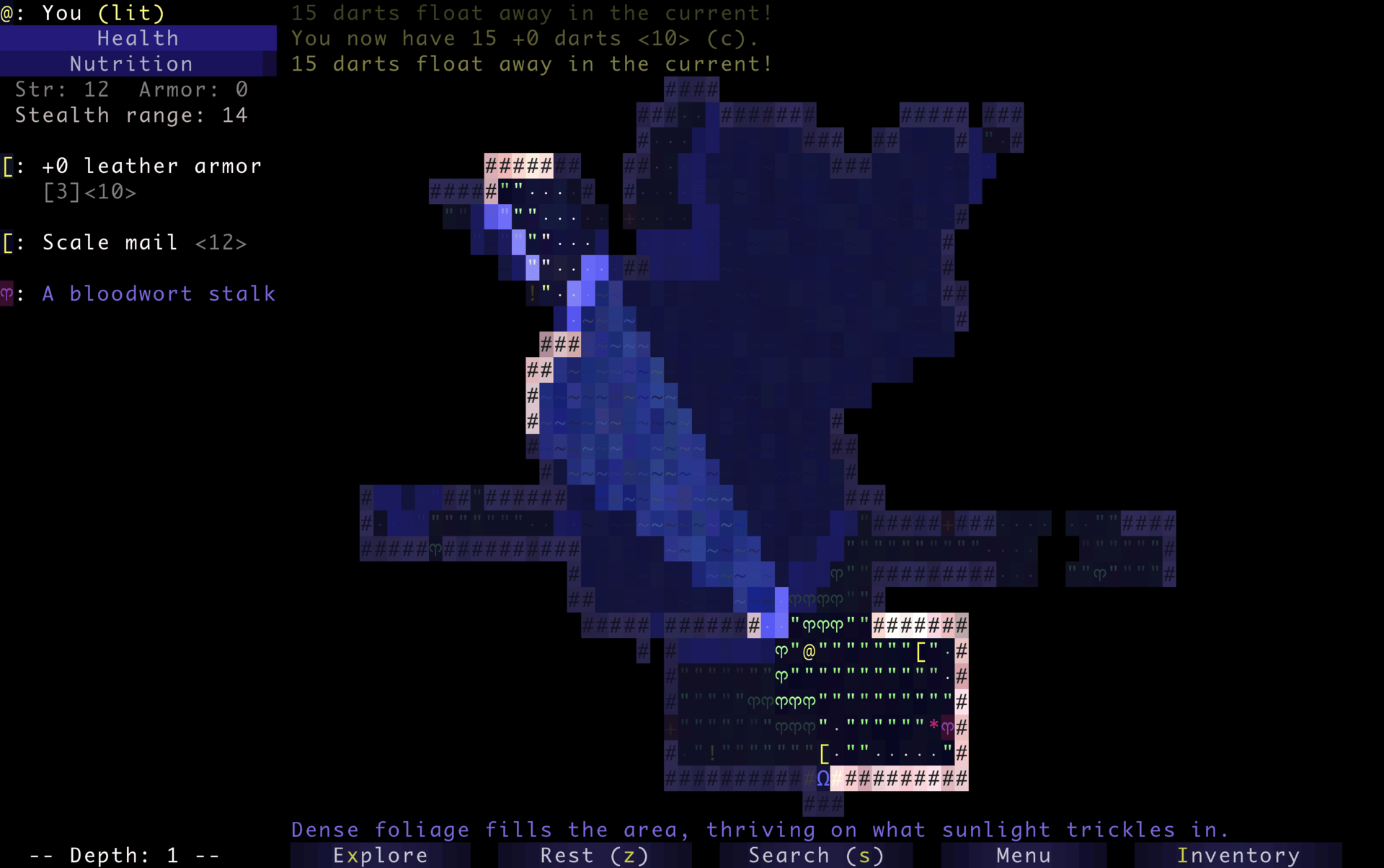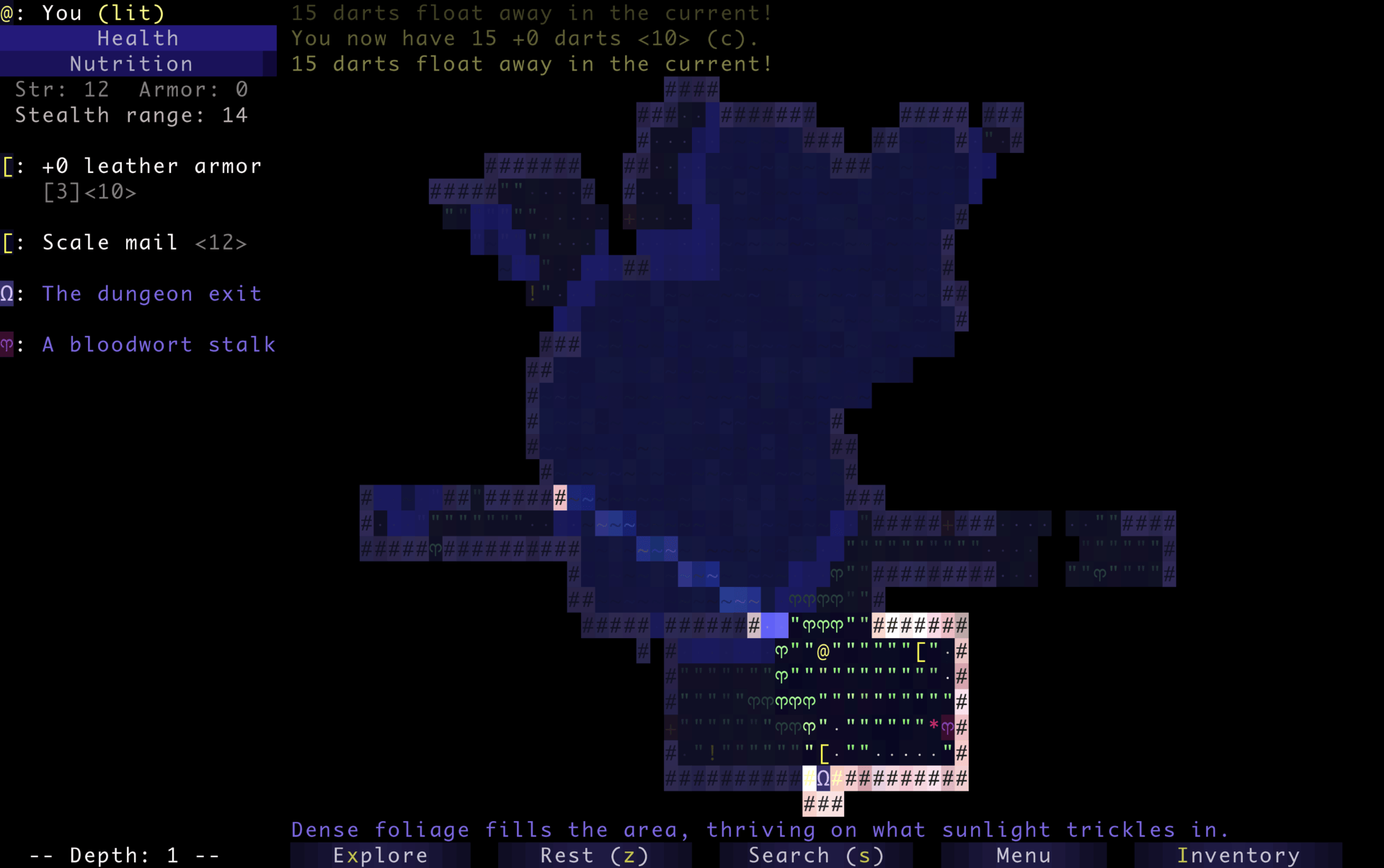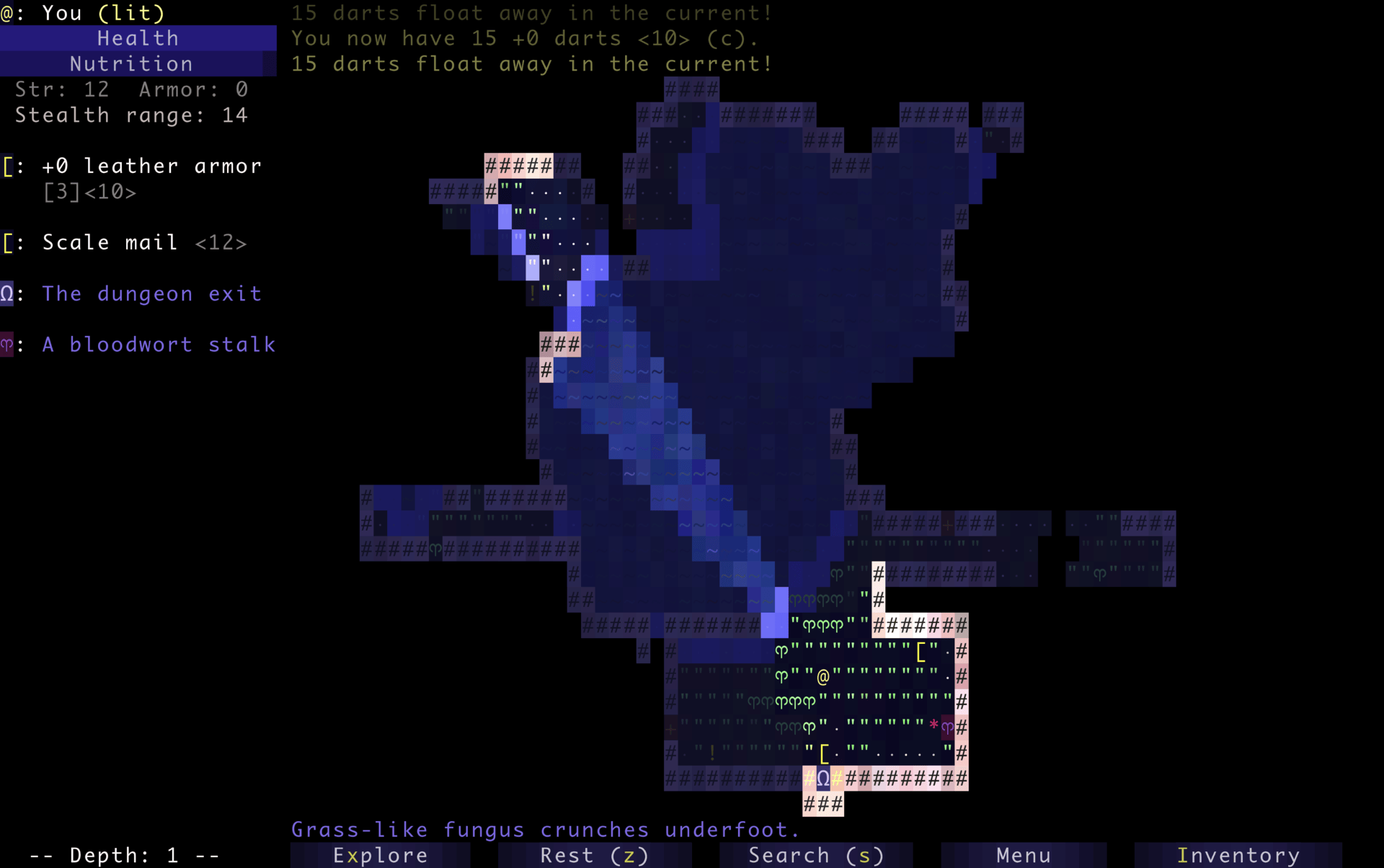
Dungeons & Desktops: 10 roguelikes that never die (because their communities won’t let them)
The first version of NetHack was released in 1987 as a heavily modified descendant of Hack, itself based on Rogue, a Unix-era experiment built for character-based terminals around 1980. The term “roguelike” later emerged in the early 1990s. This is also when Usenet communities, like rec.games.roguelike, were founded. Players and developers gathered there to trade ideas, variants, and philosophies inspired by Rogue’s design.
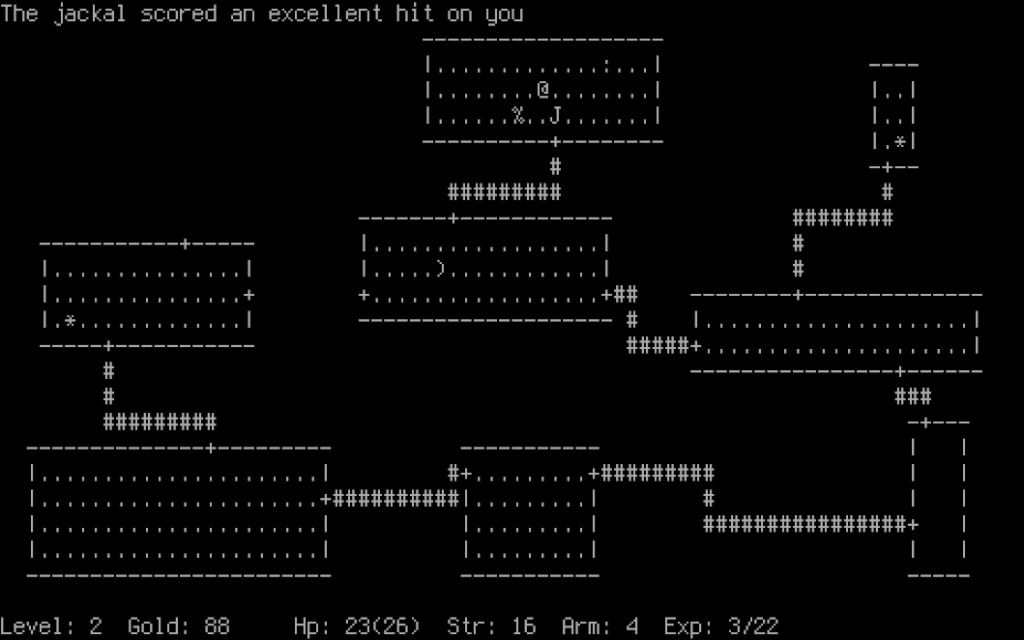
Screenshot of Rogue courtesy of the Retro Rogue Collection. The player “@” can be seen above a food item “%” and a jelly monster “J”. That lineage helps explain something unusual about the genre. NetHack was developed collaboratively over networked systems before most people even had internet access. Angband required a coordinated relicensing effort decades later just to become fully open source. And Pixel Dungeon was declared “complete”… and then immediately forked by the community into dozens of new games.
Recently, I built a small experiment that turns a GitHub repository into a roguelike dungeon. That idea came from the gaming genre that has been evolving in the open for decades, shaped as much by players as by developers. Many of the games that defined roguelikes are still actively maintained today, with contributors refining systems, debating mechanics, and layering in new ideas over time.
That same spirit shows up in events like the 7DRL challenge, where developers build a complete roguelike in seven days, and in the annual Roguelike Celebration, which brings the community together to share ideas, research, and experiments. The genre thrives in these spaces, where iteration is fast, ideas are tested in public, and even small projects can leave a lasting mark.
Here are 10 open source roguelikes you can study, contribute to, and play for hours, until you’ve totally lost yourself. Most of them started small. None of them stayed that way…
1 Cataclysm: Dark Days Ahead
C++
Cataclysm: Dark Days Ahead drops you into a world where everything has already collapsed. Cities sit abandoned, labs hum with leftover experiments, forests reclaim the edges, and the roads lead nowhere good. You scavenge through the wreckage while hunger, injury, weather, and time keep pressing in. The world runs continuously, shaped by a huge contributor base that keeps adding systems and interactions. Every building has a story baked into it. Most of them end with you running.
It started as a fork of Cataclysm and never really stopped growing. Over time, contributors kept layering in new systems, interactions, and edge cases until the simulation reached a kind of sprawling completeness. You can wire in cybernetics, mutate into something barely recognizable, or assemble an armored vehicle from whatever you can salvage. None of it is scripted. It all emerges from the rules underneath. The level of detail even spills into the community, where players argue about nutrition, crafting logic, and what should realistically exist.
🛡️ Fun fact: Its simulation is so deep that contributors regularly debate real-world topics like nutrition, physics, and crafting logic in pull requests.
2 Nethack
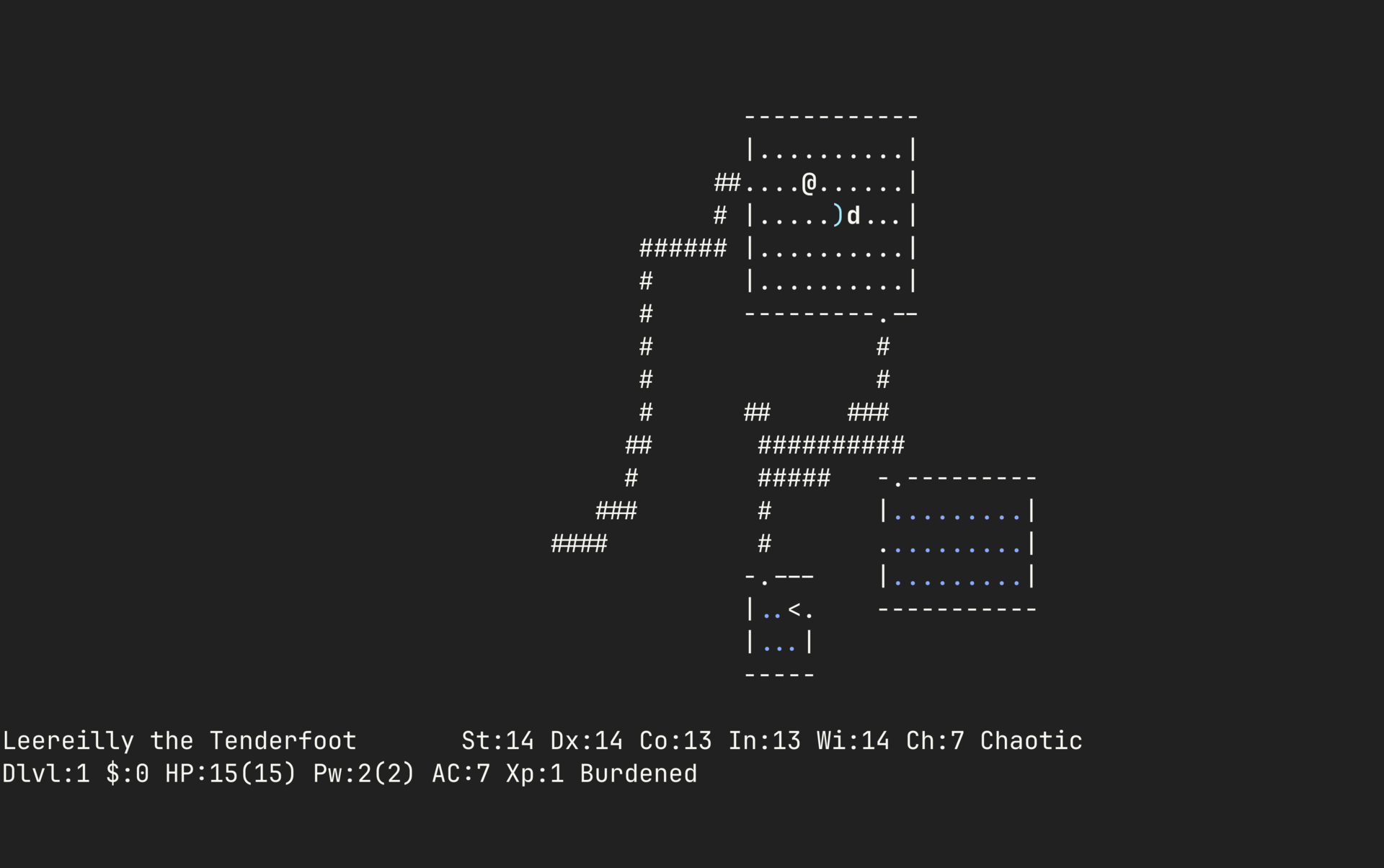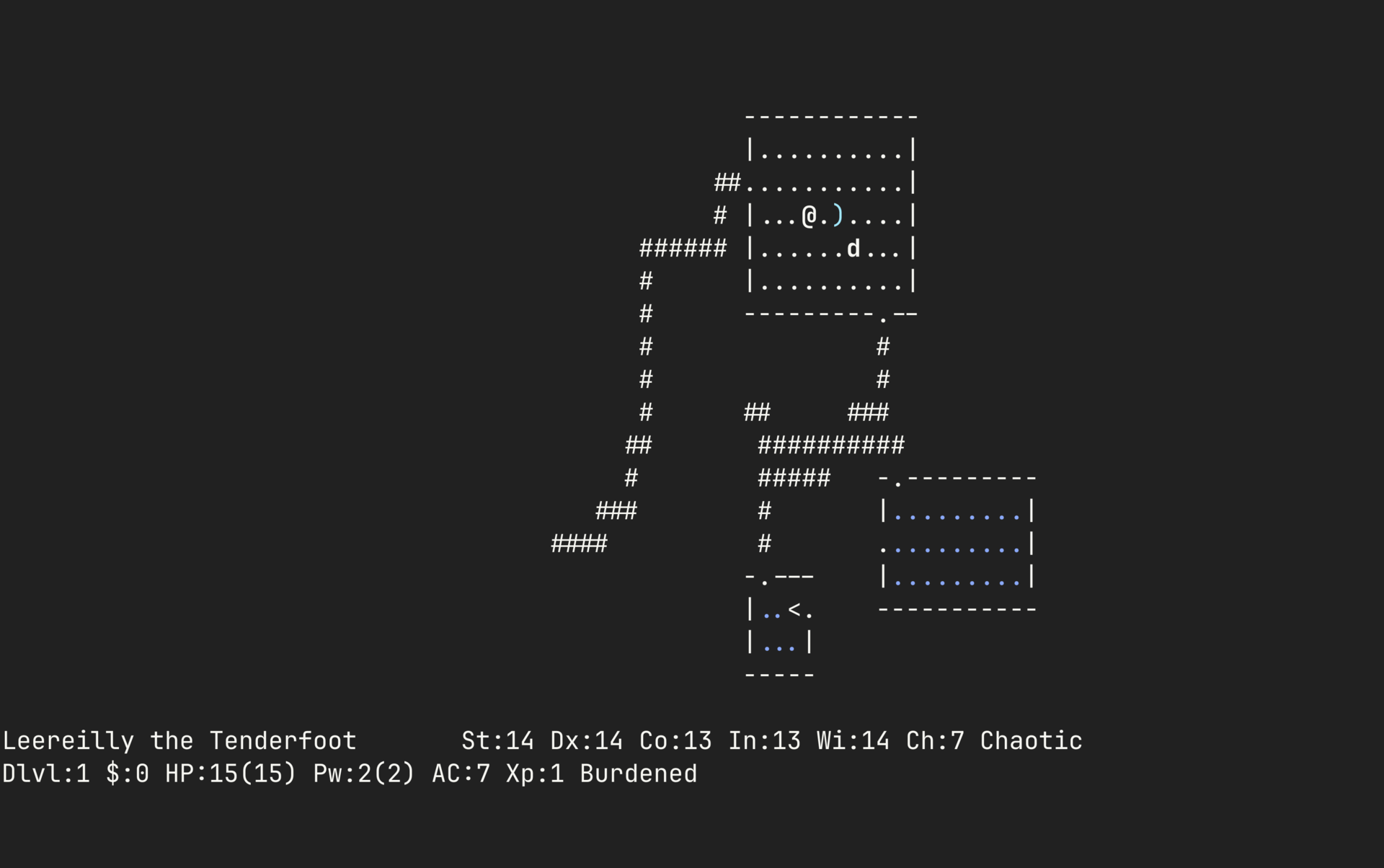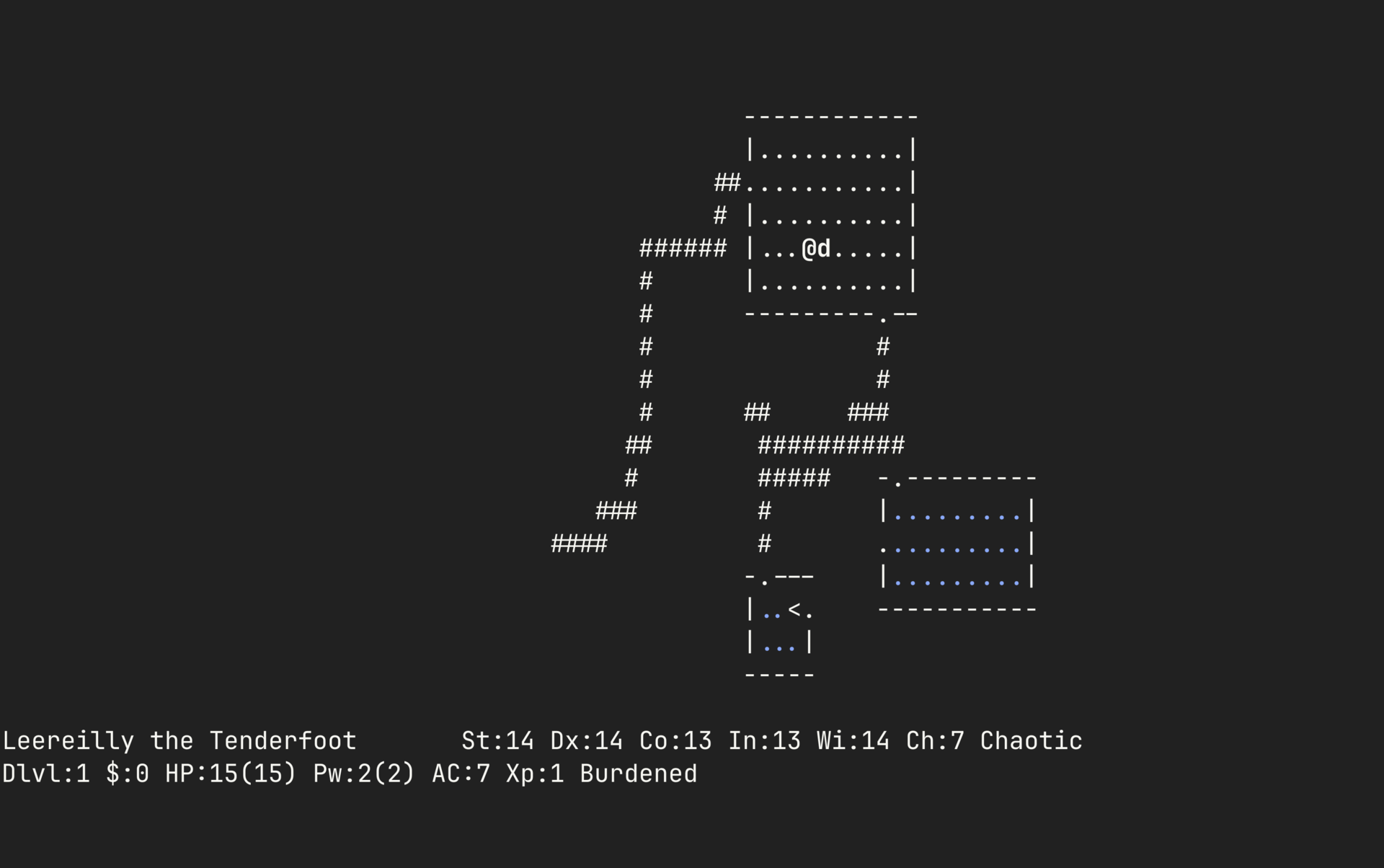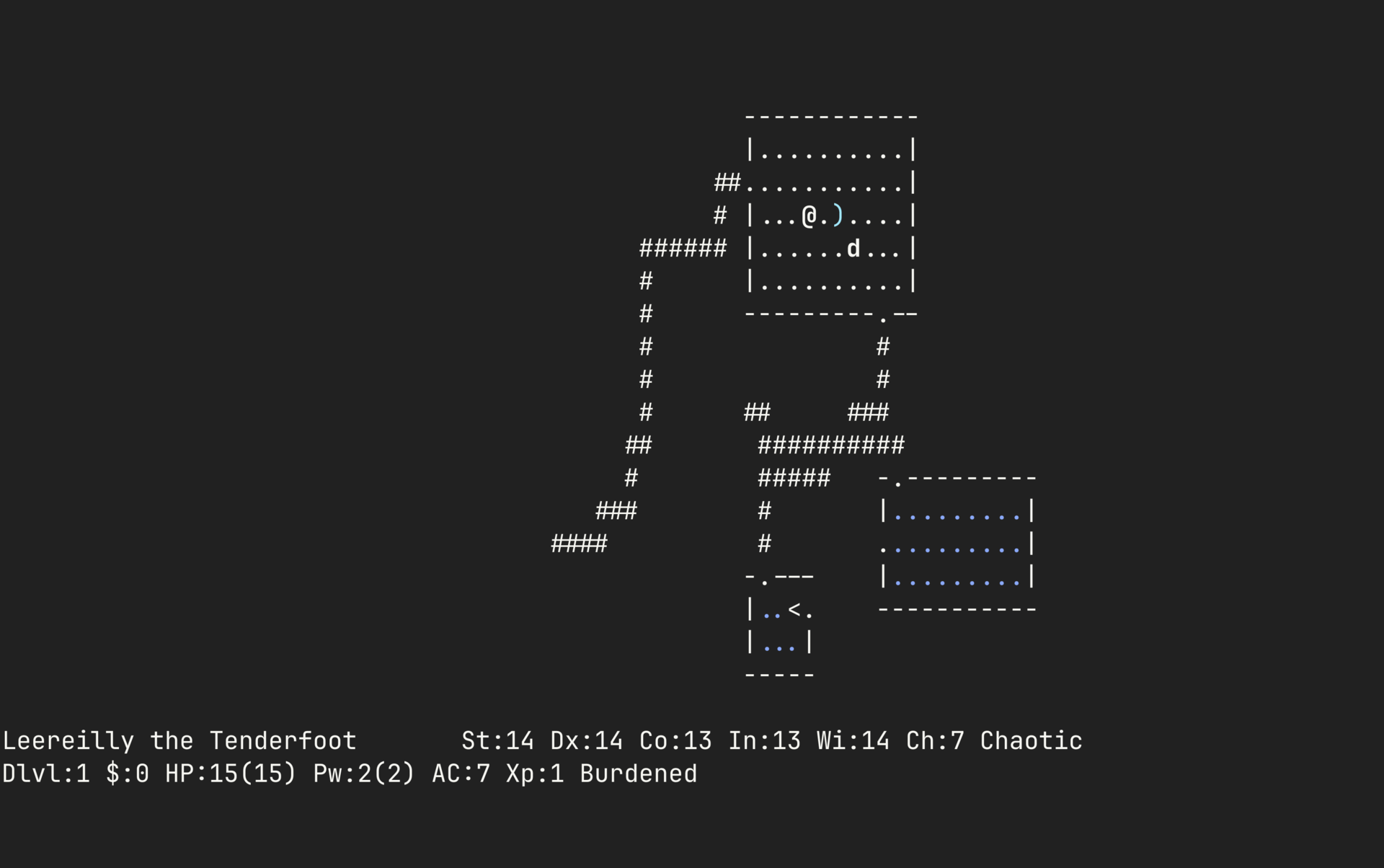
C
NetHack was first released in 1987 as a fork of Hack, the 1984 game that grew out of Rogue’s dungeon-crawling experiments. It drops you into a dungeon packed with shrines, traps, cursed gear, and monsters that seem personally invested in your downfall. Every object follows its own rules, and those rules collide in ways that feel almost vindictive. After decades of contributions, the game is dense with edge cases, hidden mechanics, and bizarre outcomes, so curiosity rarely goes unpunished. The deeper you go, the more the dungeon seems to anticipate whatever terrible idea you are about to try next.
NetHack 5.0.0 was just announced, proving that even after nearly four decades, the dungeon is still finding new ways to surprise people. Reading the release notes is always entertaining because they capture the game’s strange, systemic humor better than almost anything else: illiterate heroes who receive a spellbook from their deity get the spell shoved directly into their mind, fleeing leprechauns bury their gold after teleporting, and monsters can blind you with a camera.
If ASCII / 2D tilesets don’t do it for you, be sure to check out @JamesIV4’s 3D version(!) available on web, Windows, macOS, Linux, and Android. It uses neth4ck/neth4ck to run NetHack compiled to WebAssembly, with a React hooks/Zustand frontend handling input and UI, plus a Three.js renderer. NBD.
⚔️ Fun fact: The “Net” in NetHack comes from how it was built. It’s one of the earliest games developed collaboratively over the internet, with contributors coordinating across networks long before modern open source workflows.
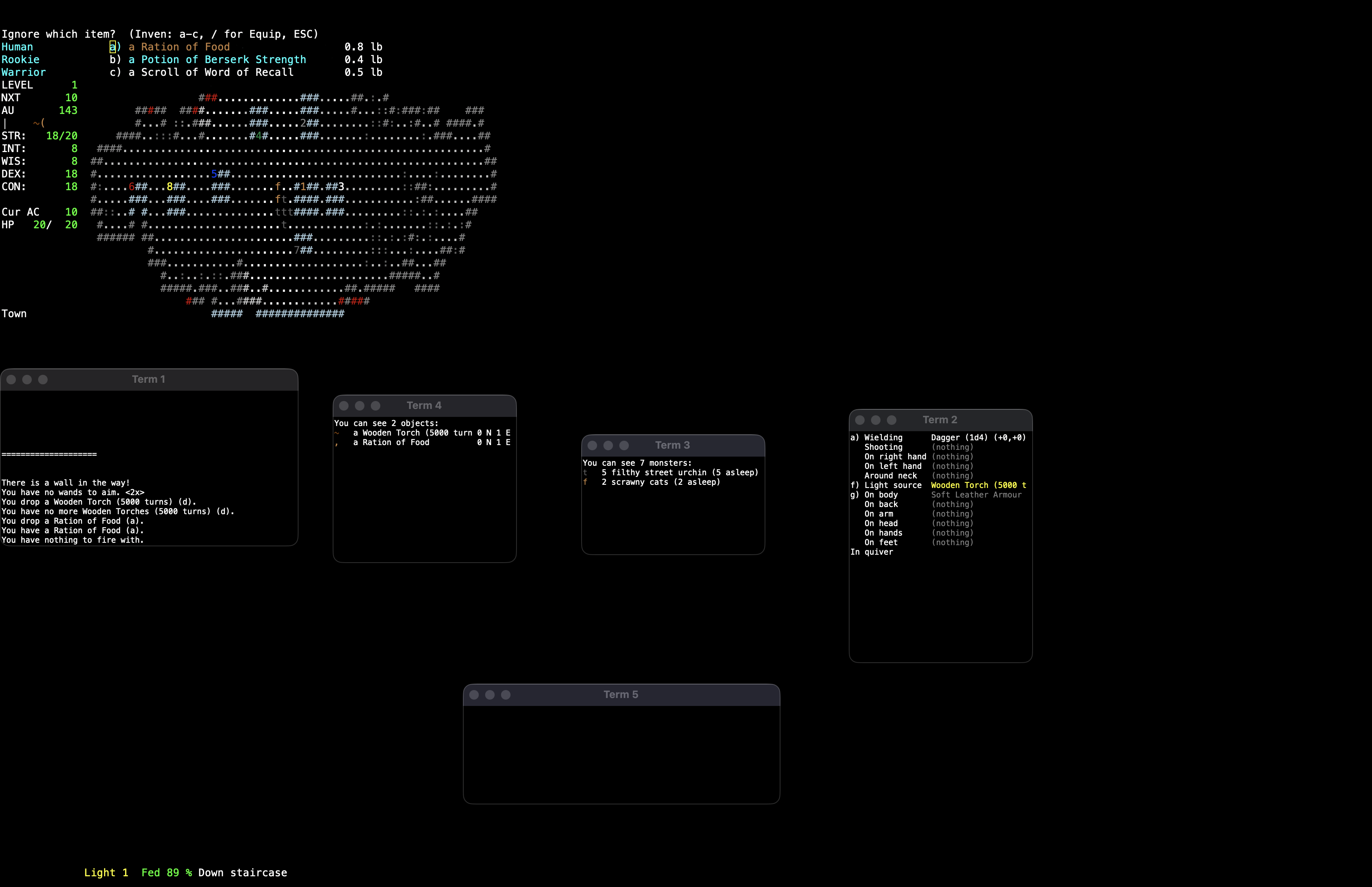
3 Dungeon Crawl Stone Soup
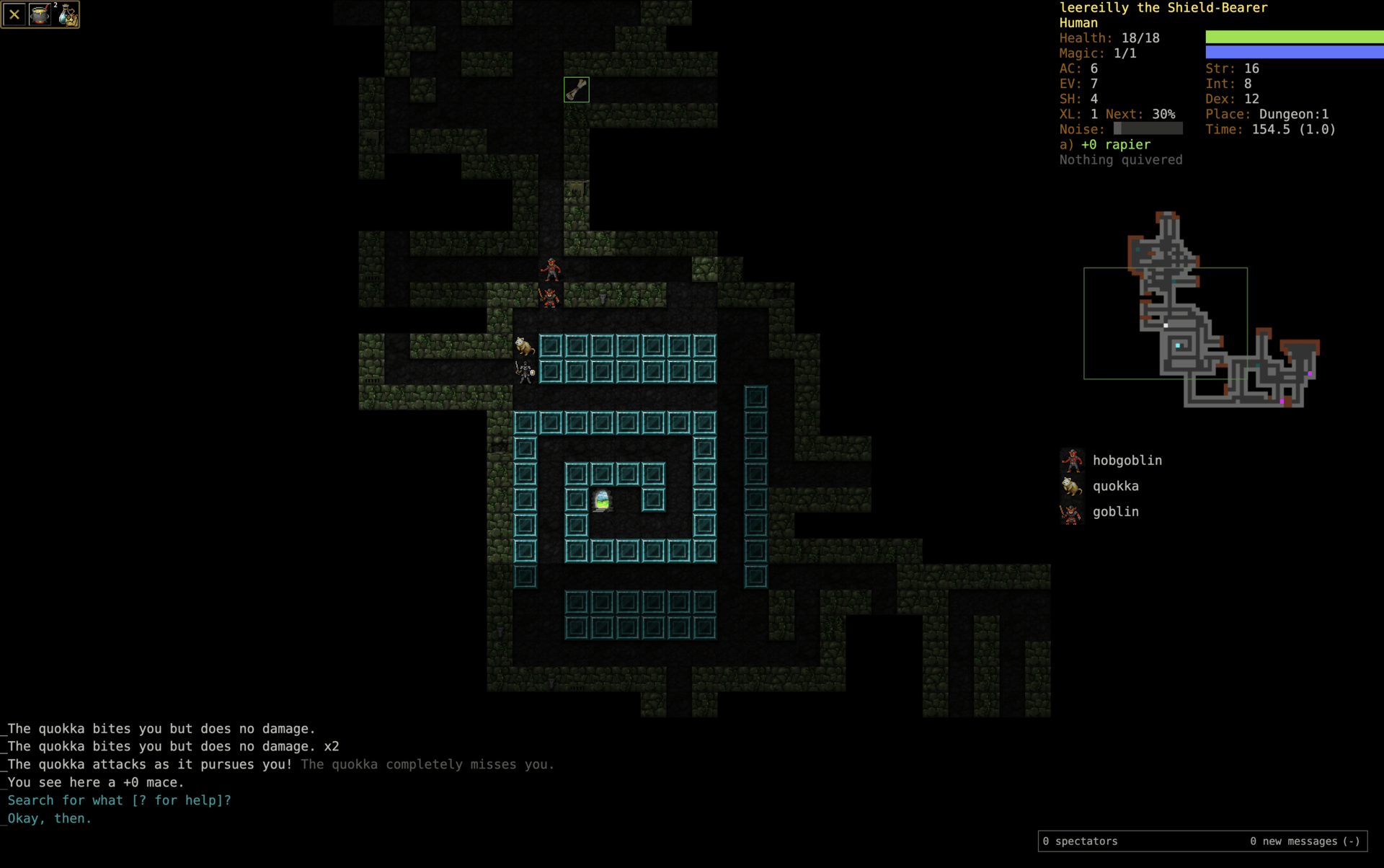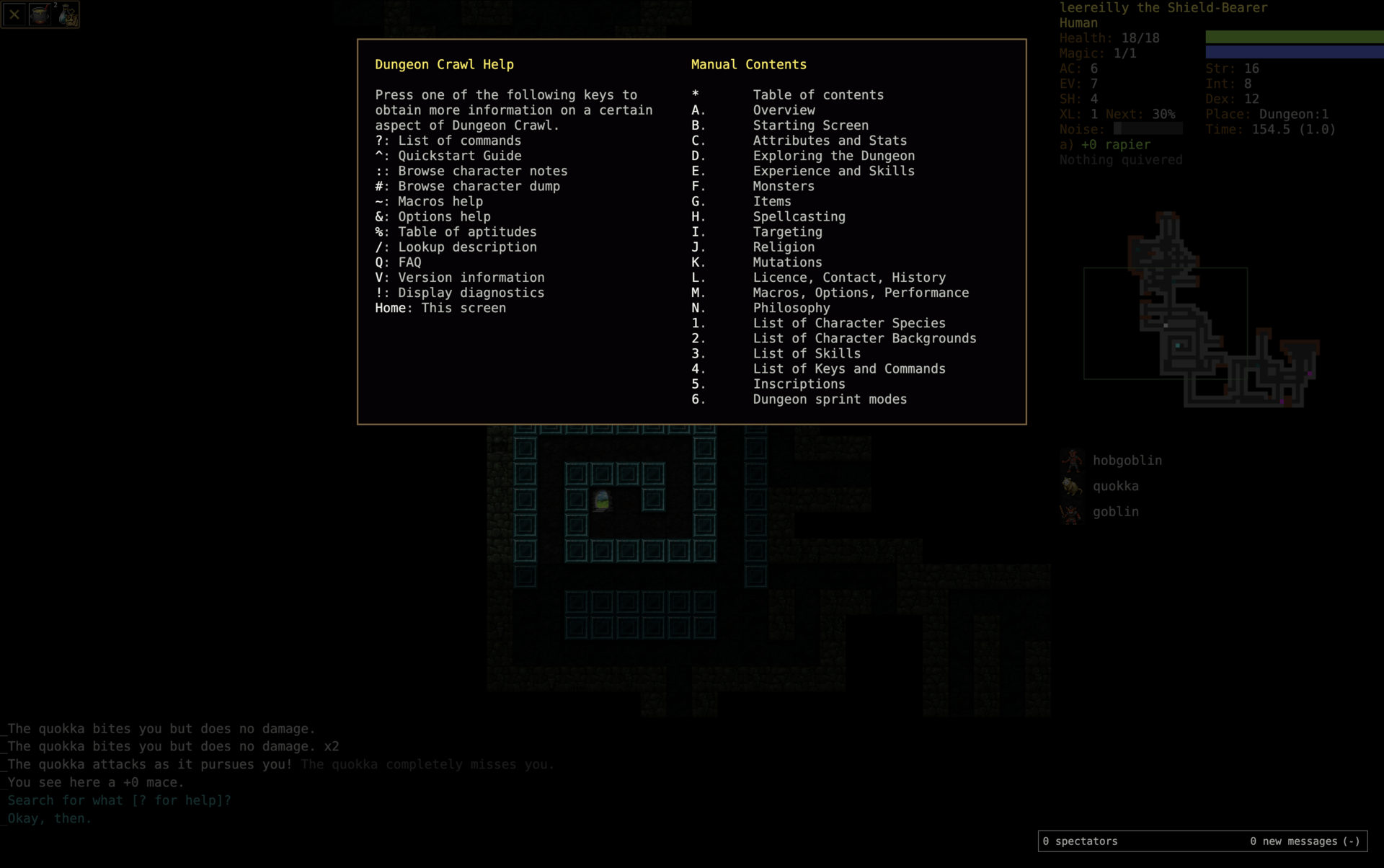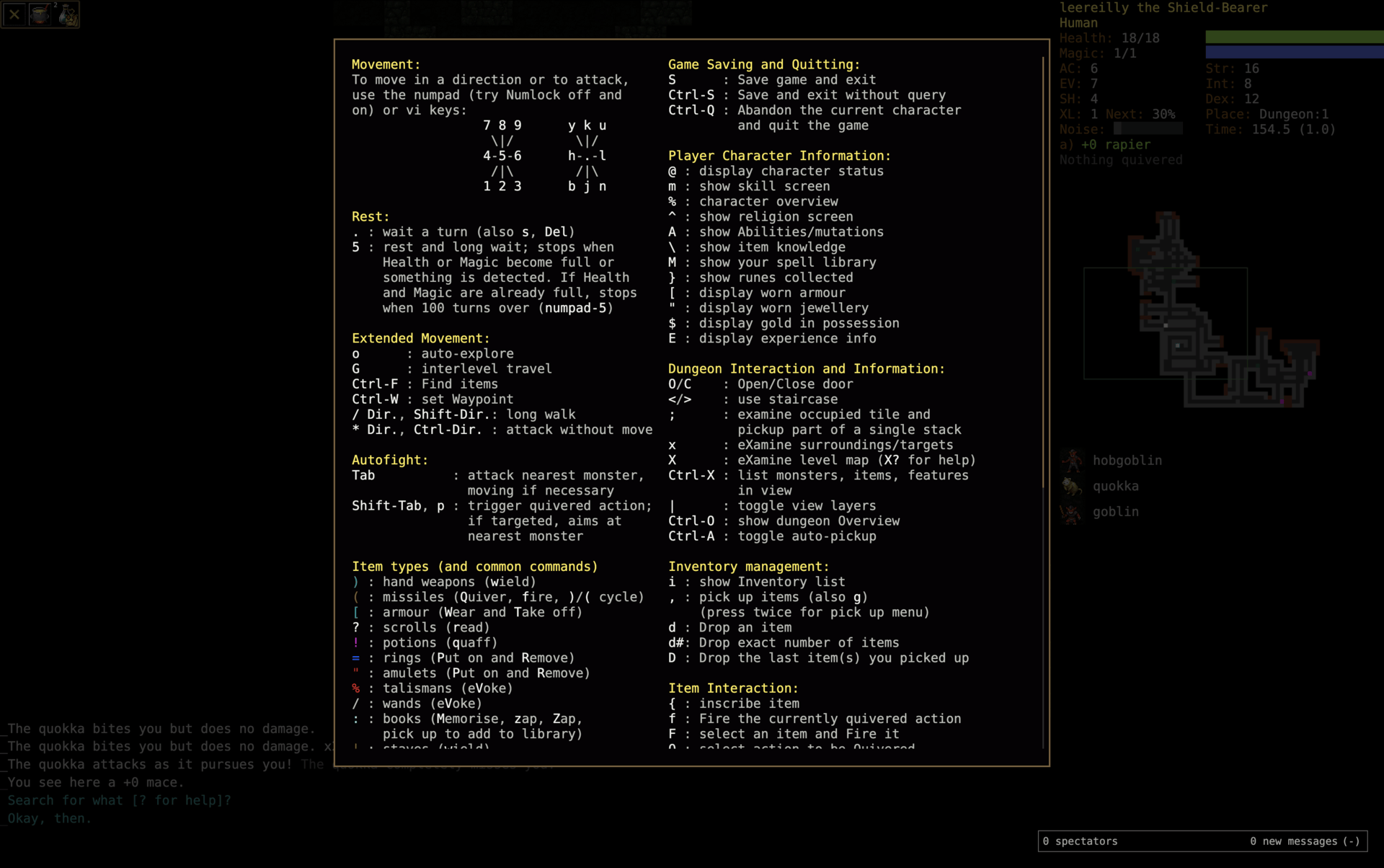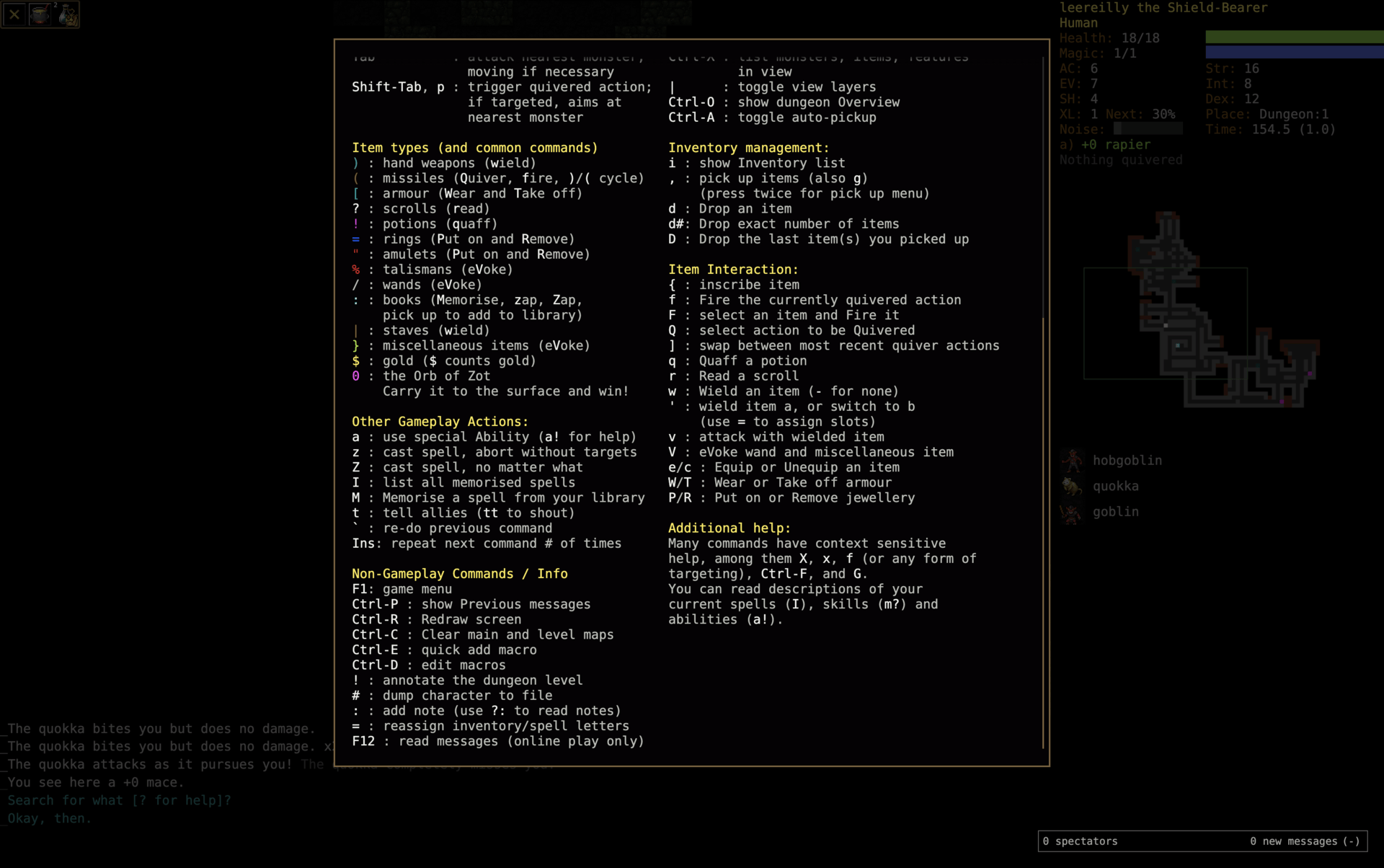
C++
Dungeon Crawl Stone Soup unfolds across a network of dungeon branches, each tuned to test a different kind of mistake. Lairs full of beasts, vaults packed with threats, deeper levels that stop pretending to be fair. You choose a species, a background, maybe a god to follow, and your choices carry through everything that comes after. Magic, religion, and skills all pull in different directions, so builds don’t settle—they evolve under pressure.
You can play offline or on public servers, where other players’ ghosts appear and people watch games unfold in real time. It’s a shared space as much as a dungeon. Resources stay tight, every decision stacks, and you deal with the outcome.
🛡️ Fun fact: Dungeon Crawl Stone Soup is what happens when a community refuses to let a project stall. Forked in 2006 to revive a slowing codebase, it’s still evolving today—sometimes by adding features, sometimes by deleting them.
4 Angband
C
Angband stretches downward from a quiet town into a massive dungeon tied to decades of development. Each level pushes deeper toward a final confrontation that has defined runs for generations. A steady contributor base keeps refining mechanics while variants and forks branch off in different directions. The structure stays familiar, but the scale and history give it weight.
It traces its lineage back to Moria in the 1980s, and it didn’t stay contained for long. Forks spun out into dozens of variants—some tweaking balance, others rebuilding systems or shifting the setting entirely. Some stay close to the original, others turn it into something barely recognizable. Ideas move between them, get reworked, and show up somewhere else a few years later.
Despite its age, it’s still being updated. Around it sits a community that keeps things moving—ladders, forums, live servers where people watch runs unfold in real time.
⚔️ Fun fact: Angband didn’t start fully open source—it took a coordinated relicensing effort in 2009 to get there. Decades of contributors had to align to make it happen, turning one of the oldest roguelikes into something the community could truly take forward.
With the transition to GitHub, Angband’s development split into distinct branches: a stable mainline and experimental offshoots. This shift led to what David L. Craddock describes as an “explosion of productivity,” with new versions appearing almost nightly. These development branches functioned like a “secret lab,” where the dev team’s “mad scientists” could freely experiment—building and discarding features without risking the integrity of the official release.
This branching model not only accelerated development but also made experimentation sustainable. (Craddock, Dungeon Hacks)
5 Brogue Community Edition
Brogue presents a dungeon built with clarity and intent. Rooms connect in ways that funnel you into decisions you cannot ignore. Light drops off into darkness, fire spreads through terrain, gas drifts, and the environment joins every fight. Each floor feels deliberate, with just enough unpredictability to keep you alert. When things go wrong, you can trace the moment it started.
That clarity has also led to a surprisingly active mod scene, with dozens of community variants experimenting on top of the same foundation—some adding new monsters and items, others reworking pacing, visuals, or the feel of a run entirely (see the full list).
🛡️ Fun fact: The original Brogue stopped receiving official updates years ago, but the community didn’t leave it there. Development continued as Brogue Community Edition, with contributors picking up the codebase and still shipping new releases today.
6 Pixel Dungeon
Java
Pixel Dungeon is structured as a series of quick-hit layers. Sewers give way to prisons, then caves, then worse. Every level adds a small twist—a trap, a new enemy, a bad surprise behind a door you probably should not have opened. Built as a free passion project with no monetization hooks, it leans on tight design and fast pacing. Runs are short. The urge to start another one is not.
⚔️ Fun fact: Pixel Dungeon went open source in 2014 and was declared “complete” a year later. The community took that as a starting point, not an ending… spinning up dozens of forks and variants that are still being updated today.
7 Shattered Pixel Dungeon
Java
Shattered Pixel Dungeon takes that structure and pushes it further. Regions feel more distinct, enemies and items open up viable paths, and regular updates keep reshaping the experience. The dungeon keeps growing without losing its pace. Community feedback feeds directly into development, so the world keeps shifting under players who thought they had it figured out.
🛡️ Fun fact: Shattered Pixel Dungeon started as a small balance mod and quietly turned into a full game over years of continuous updates. A decade later, it’s seen dozens of releases, millions of downloads, and is widely considered one of the best open source games out there—all while sticking to pure roguelike principles with no permanent upgrades, just better decisions each run.
8 DRL
Free Pascal
DRL runs through military bases and hell-infested corridors filled with familiar threats and very loud intentions. Tight levels, heavy weapons, and encounters that escalate fast. The structure stays turn-based, but the pressure feels immediate. Built in Free Pascal and fueled by 90s shooter DNA, it delivers short runs that hit hard and end fast if you hesitate.
DRL is a fast and furious, coffee-break length roguelike game that is heavily inspired by a certain popular 90s FPS game.
⚔️ Fun fact: DRL started life as “Doom, the Roguelike,” before a trademark notice forced a rename—ironically speeding up its transition to open source. It’s been evolving since the early 2000s and still gets updates today, all while turning one of the fastest FPS games ever made into a turn-based roguelike that somehow keeps the same intensity.
9 KeeperRL
C++
KeeperRL begins underground, where you carve out rooms, lay traps, and build a dungeon designed to break incoming heroes. The surface world pushes back with raids, while your minions train, craft, and occasionally cause problems of their own. You can step in directly for tactical combat or let the systems play out. Fire spreads, creatures react, and the dungeon develops a personality that reflects your decisions.
🛡️ Fun fact: KeeperRL leans hard into its open source roots. You can buy the full version by donating to wildlife charities, grab a completely free ASCII build if you prefer a terminal experience, and even get help from the developer compiling it yourself.
10 HyperRogue

C++
HyperRogue spreads across dozens of strange lands where geometry refuses to cooperate. Paths diverge in unexpected ways, space expands faster than expected, and returning to a familiar spot takes more precision than it should. Each region introduces its own rules, enemies, and hazards, all layered on top of that shifting foundation. Movement alone becomes a skill you have to learn under pressure.
HyperRogue takes the familiar loop of a roguelike—moving, surviving, collecting, and adapting—and places it in a world where the rules of space no longer behave as expected. Built on hyperbolic geometry, its world expands faster than intuition can track, making navigation as challenging as combat. Paths that seem parallel drift apart, returning to a previous location requires deliberate precision, and positioning against enemies forces you to learn a new spatial logic under pressure. Each of its many distinct regions adds unique mechanics, hazards, and creatures on top of this unstable foundation, constantly reshaping how you approach the game. Despite its abstract design, the core remains direct: gather treasure, avoid being overwhelmed, and push deeper as the difficulty scales. The result is a roguelike that feels less like exploring a dungeon and more like learning the rules of an unfamiliar universe one mistake at a time.
⚔️ Fun fact: HyperRogue doubles as a long-running research project. Its developer, @ZenoRogue, continuously experiments with hyperbolic geometry, adding new lands, mechanics, and systems that explore how games behave when the rules of space itself change.
Maintained by community
What stands out across all of these projects is how active they still are. People are adding systems, revisiting old decisions, and pushing mechanics into weird corners just to see what holds up. Some have evolved with updated graphical interfaces, others stay true to their terminal roots, and a few let you switch between both. You see the same thing happening around them too, in tools like Ghostty, Charm’s suite, and Ratatui, where the terminal keeps getting stretched in new directions.
Tight loops, visible systems, communities that don’t drift away. That’s what keeps roguelikes here—and the CLI is built on the same foundation.
These projects don’t die. They just get forked.
Thanks for reading, adventurer. May your next run end slightly better than the last! ⚔️
11 Special bonus roguelike-like game
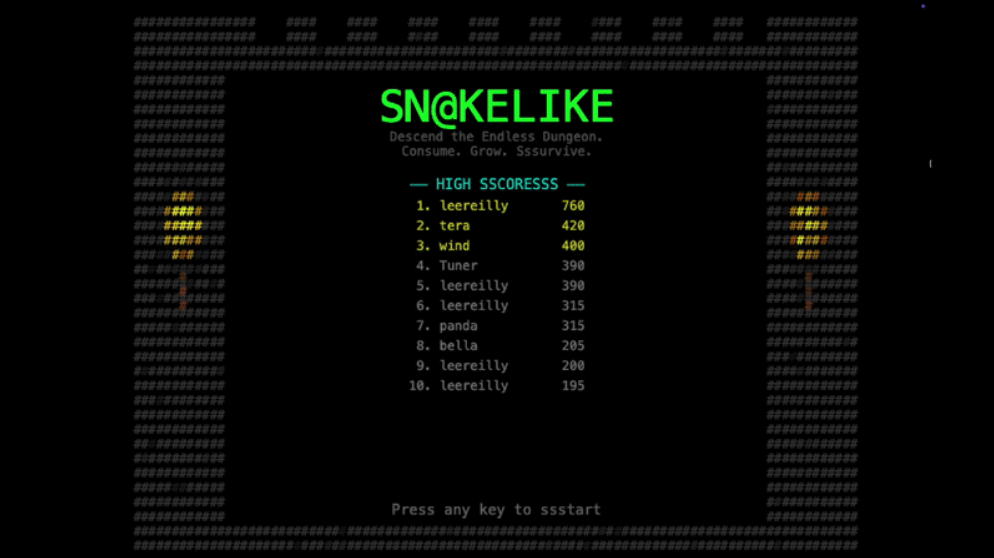
YARLM (Yet Another Roguelike Lee Made) called Snakelike, a daring mix of Rogue and Snake that I conjured using GitHub Copilot for the umpteenth annual 7DRL Challenge. Ssseee if you can beat my high ssscore. 🐍
The post Dungeons & Desktops: 10 roguelikes that never die (because their communities won’t let them) appeared first on The GitHub Blog.
-

Here are 40 of our favorite deals from REI’s massive Anniversary Sale

The last-gen InReach Mini 2 might require a subscription to use, but we guarantee it’s far more durable than your phone. | Image: Garmin REI’s annual Anniversary Sale — the retailer’s biggest of the year — has arrived, bringing with it discounts on all kinds of outdoor essentials. If you’ve got a camping trip coming up, now is a good time to stock up on the basics, whether it be a tent, sleeping pad, or stove. If your summer plans involve hiking or heading into the backcountry, there are also savings to be had on everything from Garmin watches to water filters, some of which are also on discount at retailers like Amazon.
The sale runs through May 25th, and to save you time scrolling, we’ve rounded up the best deals below. Additionally, as in previous years, REI members get 20 percent off one full-price item or one REI Outlet item with code ANNIV26, giving those who pay for a lifetime membership ($30) even more ways to save in the run-up to Memorial Day.
Smartwatches and fitness trackers
Garmin Fenix 8
The Garmin Fenix 8 is a premium multisport watch that features a speaker, mic, and on-device assistant for calls, timers, and voice commands. It also offers elite battery life, dual-frequency GPS, and robust sensors. Read our review.
Where to Buy:
Amazfit Active 2
The Amazfit Active 2 delivers outsized value for the price. It looks spiffy and has a wide array of health tracking features, plus built-in GPS and AI chatbots to provide extra context to your data. Read our review.
Where to Buy:
- Garmin’s Venu 4 is geared toward the average athlete, and it’s on sale at REI, Amazon, and Best Buy in both size configurations for $499.99 ($50 off), matching its best price to date. The wearable offers many of the same health and fitness tracking features as its predecessor, the Venu 3S, including abnormal heart rate alerts, detailed sleep insights, audio-guided meditation sessions, and a wheelchair mode. It introduces new wellness features, though, including the ability to track caffeine and alcohol intake, as well as Garmin Coach, so you can tailor workouts based on your fitness history, sleep quality, and recovery.
- REI, Amazon, and Best Buy are also selling the Garmin Lily 2 Active for $249.99 ($50 off), which is its lowest price to date. The stylish smartwatch is a great budget-friendly Garmin, especially for people with smaller wrists. Like the standard Lily 2, it offers basic fitness tracking, notifications, and up to five days of battery life; however, the so-called “Active” model adds a physical button, built-in GPS, and support for more sports tracking. Read our Lily 2 review.
- If you want more accurate heart rate tracking than most smartwatches offer, Polar’s H10 is on sale at REI and Amazon for $94.49 ($10 off), which is one of its better prices in recent months. Unlike wrist-based trackers, the chest strap records your heart rate directly from your chest for more precise readings during workouts. The lightweight sensor also pairs with a wide range of fitness apps, smartwatches, gym equipment, and other devices via Bluetooth, and it’s water-resistant enough for swimming.
Communication and safety gear
Garmin inReach Mini 2
Garmin’s palm-sized inReach Mini 2 satellite communicator offers off-the-grid two-way messaging, built-in navigation capabilities, and powerful mapping features, including the ability to set waypoints when paired with Garmin’s Explore app. A subscription plan is required to access the Iridium network, though, with prices starting at $7.99 a month.
Where to Buy:
- Garmin’s InReach Messenger Plus is on sale at REI, Amazon, and direct from Garmin for $299.99 ($100 off), its lowest prices to date. The subscription-based Plus model provides satellite connectivity and access to emergency services like the aforementioned InReach Mini 2, except it can also send photos and audio clips in addition to standard text messages.
- Garmin’s newer InReach Mini 3 is also available from REI, Amazon, and Garmin for $399.99 ($100 off), its best price to date. Like the Mini 2, the rugged, palm-sized satellite communicator lets you send texts, share your location, check the weather, and trigger SOS alerts when you’re off the grid, all while offering battery life that can outlast your average smartphone. Unlike its predecessor, though, it features a color touchscreen, which makes it’s much easier to scroll through menus and bang out messages.
Garmin InReach Mini 3 Plus
The Mini 3 Plus is identical to the standard model in that it allows you to stay connected while off the grid; however, it also features an audible siren and the ability to send photos and voice messages, in addition to standard texts.
Where to Buy:
- The Chapter MIPS Bike Helmet is on sale starting at around $112 ($41 off) at Amazon and REI, which nearly matches its best price to date. The lightweight helmet features a hidden PopLock for securing it with a U-lock or chain. It also features a sleek visor and a Micro-USB taillight with 30 lumens of brightness, one that will automatically turn on when magnetically attached to the helmet.
- Garmin’s Varia RTL515 Radar Taillight is on sale at REI and Amazon for $149.99 ($50 off), nearly matching its lowest price to date. The headlight combines a bright LED light with a rearview radar that, when paired with a compatible device, warns you of cars approaching from behind from up to 153 yards away.
Portable Bluetooth speakers
JBL Charge 6
The Charge 6 is a robust, IP68-rated portable speaker with up to 28 hours of battery life and support for lossless audio over USB-C. Like the JBL Flip 7, it can also analyze your audio to deliver clearer, louder sound and reduce distortion at higher volumes.
Where to Buy:
- You can buy JBL’s Flip 7 speaker for $99.95 ($50 off) at REI, Amazon, and Best Buy, which matches its best price to date. The portable gadget features several upgrades over its predecessor, including a more rugged design, an enhanced tweeter, and an additional two hours of playtime. It also features JBL’s AI Sound Boost technology, which can boost the speaker’s volume without introducing distortion. An IP68 rating, meanwhile, means you can use it by the pool, while a PushLock system lets you attach interchangeable accessories like the included wrist strap.
- If you want an even smaller portable speaker, JBL’s Clip 5 is on sale for around $59 ($20 off) at REI, Amazon, and Best Buy, which is $10 shy of its all-time low. The Bluetooth speaker features an integrated carabiner that makes it easy to clip onto a backpack, bike, or beach bag, along with an IP67 waterproof and dustproof rating. It also offers up to 12 hours of battery life, so it should easily last you the day.
Cooking equipment
MSR PocketRocket 2 Stove
The PocketRocket 2 is a single-burner canister stove that can boil water in as little as three and a half minutes. It’s lightweight, foldable, and compatible with most isobutane-propane fuel canisters, making it a great pick for backpackers looking to shed weight.
Where to Buy:
LifeStraw Peak Series Straw
LifeStraw’s redesigned Peak Series Straw features a durable, leakproof design that’s great for backcountry treks. It can remove unwanted viruses, bacteria, and microplastics as you drink — just like the base model — but benefits from an increased flow rate and more premium materials.
Where to Buy:
- If you’re looking for a more convenient, all-in-one solution, the LifeStraw Go Series 1L is also on sale for an all-time low of around $34 ($11 off) at REI and Amazon. The BPA-free water bottle features a built-in two-stage filtration system, including a carbon filter that’s designed to reduce odors and improve taste, making it a solid pick for everything from travel to your daily commute.
- It’s not the most exciting thing in the world, but the GoBites Bio-Uno Long spork is on sale at REI in multiple colors for a cool $5.93 (about $3 off). The Verge’s Brandon Widder has used the sturdy, BPA-free utensil in the backcountry numerous times over the years, mainly because it’s relatively lightweight and saves you from having to pack more than one tool for devouring whatever freeze-dried concoction you opted for.
JetBoil MiniMo Cooking System
JetBoil’s cooking systems aren’t for ultra-light backpackers; however, the MiniMo is incredibly straightforward to use, comes with a 1-liter pot, and heats water in as little as two minutes, making it suitable for everything from freeze-dried meals to a well-deserved cup of cocoa.
Where to Buy:
Coleman Cascade Classic Camp Stove
Coleman’s go-to stove provides everything you need for simple, reliable camp cooking. It’s got enough power to handle most meals, as well as a pair of burners for cooking multiple things at once. It also features a matchless push-button igniter and built-in wind guards.
Where to Buy:
- Coleman’s Cascade 3-in-1 Stove is on sale for around $204.99 ($70 off) at REI, Backcountry, and Coleman’s online storefront. It’s a better pick for campers who want to cook a little more than basic meals on a standard two-burner stove. In addition to two adjustable burners with wind guards and matchless ignition, it comes with interchangeable grill and griddle attachments, making it easier to cook things like eggs and burgers without packing extra gear.
- The BearVault BV500 Journey is on sale for around $79.89 ($20 off) from both REI and Campman. The hard-sided bear canister is designed to keep wildlife out of your food while offering 11.5 liters of storage, which is enough for about a week’s worth of meals and snacks. Despite its rugged build, it’s relatively lightweight, and the screw-top lid is designed to be secure without requiring complicated tools. As an added bonus, it also doubles as a makeshift camp stool.
Shelter, sleep, and furniture
Kelty Low Loveseat
The Kelty Low Loveseat is a sturdy, low-profile camp chair built for two. It features a steel frame, a padded seat, and extra-large cup holders for your drinks or gear. It also includes a padded roll-tote storage bag, making it easy to transport when it’s folded down.
Where to Buy:
Exped MegaMat Duo
The MegaMat Duo is a four-inch, self-inflating mattress that’s become one of our favorites thanks to its extra-wide design. It uses a combination of open-cell polyurethane foam and generous padding for comfort, which helps keep you warm when temperatures dip. It also makes for a stellar air mattress for guests.
Where to Buy:
- A small, compact chair is nice to have for lounging by the campfire, and REI’s Flexlite Camp Chair is a great option now that it’s down to $67.39 (about $22 off) in multiple colors at REI. It features an aluminum frame, a stable four-leg design, and a ripstop polyester seat with water and stain resistance. When you’re done, it can also quickly fold down into a drawstring bag, so you can throw it in your car or tent.
- You can get the Therm-a-Rest Z Lite Sol for $44.89 ($11 off) at REI right now. It’s a relatively lightweight, compact sleeping pad with an accordion-style design that lets you attach it to your backpack. The closed-cell foam also provides comfort after a long day of hiking, while the sleeping pad’s surface helps reflect radiant heat back to your body, so you can stay warm in the fall.
Half Dome 2 Tent (with footprint)
REI’s inexpensive, three-season tent is easy to set up and offers plenty of space for two people, with built-in pockets for stowing gear and large roll-up doors. It’s certainly not the lightest offering you can buy, but at this price, it’s an easy recommendation for first-time backpackers and anyone looking for a solid tent for car camping.
Where to Buy:
Rumpl Original Puffy Blanket
Rumpl’s classic lightweight blanket features synthetic insulation for warmth, a weather-resistant outer shell, and a stuff sack. It also comes in an array of attractive designs and pairs with Rumpl’s Cape Clip, so you can wear it hands-free.
Where to Buy:
- REI is currently selling its Magma 30 Sleeping Bag in a variety of sizes starting at $209.39 ($139 off). The bag uses 850-fill-power, water-resistant down for warmth and weighs under 20 ounces, depending on the size, making it a great budget pick if you’re looking to get into ultralight backpacking. It also includes a hood to help retain heat, extra room around the feet, and a terrific zipper design that’s less likely to snag when you’re crawling in or out.
- REI is selling GCI’s Freestyle Rocker Chair for $47.93 ($32 off). It’s a more comfortable alternative to your average camping chair, one that rocks and can handle both hard and soft ground. It also features padded armrests, a built-in beverage holder, and a foldable design, which makes it easy to throw in the back of your car before heading out the door.
REI Siesta Hooded 20 Sleeping Bag
The Siesta prioritizes comfort with a roomy rectangular shape that gives you space to stretch out. The synthetic sleeping bag features an insulated hood — one that’s spacious enough to accommodate a real pillow — along with multiple zipper configurations so you can vent your feet or fully unzip it into a quilt-like blanket.
Where to Buy:
Headlamps and camp lighting
BioLite Site Lights
BioLite’s ultra-versatile Site Light kit comes with six weatherproof bulbs, which can illuminate up to 1,000 square feet when hung or properly staked. You don’t need to bring a charger, either, as the included carrying case doubles as a solar charger for the lights.
Where to Buy:
Black Diamond Spot 400 Headlamp
Black Diamond’s 400-lumen headlamp offers adjustable brightness, a red night vision mode, and an IPX8 waterproof rating, so it can handle rainy nights. It’s also dual-fuel compatible, meaning you can use standard AAA batteries or use it in tandem with Black Diamond’s rechargeable BD 1500 Li-ion battery for added flexibility.
Where to Buy:
- The Petzl Tikka is on sale at REI for $19.73 (about $15 off). The basic headlamp is a great option that features a max output of 350 lumens, tilt functionality, and an IPX4 rating, making it safe to use in light rain. It also features a lock function that prevents it from accidentally turning on when packed.
- The Nite Ize Radiant 314 — which is currently down to $31.73 (about $13 off) at REI — provides 314 lumens of brightness, an impact-resistant design, and an IPX4 rating for water resistance. The rechargeable lantern can also last up to 96 hours on a single charge, while the built-in power bank can provide an extra boost of power to your phone in a pinch.
- BioLite’s Luci Charge 360 is available for $44.89 ($16 off) from both REI and BioLite, which is a terrific price for the inflatable lantern. Its collapsible design makes it easy to pack, and it offers up to 360 lumens of adjustable brightness. The waterproof gadget also lasts for 50 hours on a single charge, and when it dies, it’s easy to recharge via solar power or USB-C. Plus, you can use it as a power bank, allowing you to top off your phone or other small devices when outlets aren’t nearby.
Mpowerd Luci Solar String Lights: Color
Mpowerd’s solar-powered string lights are perfect for camping or a backyard shindig. The 18-foot string can display six colors and last up to 15 hours on a single charge; the case also doubles as a charger, allowing you to top off your phone in a pinch.
Where to Buy:
Black Diamond Moji Plus Lantern
The Moji Plus offers 200 lumens of warm, dimmable light and adjustable brightness, along with an IPX4 rating for water resistance. It also features a double-hook design and the same dual-fuel tech as the Spot 400 Headlamp, meaning you can use it with standard AAAs or Black Diamond’s rechargeable BD 1500 Li-ion battery.
Where to Buy:
Miscellaneous outdoor deals
Zippo HeatBank 6 Pro Rechargeable Hand Warmer
Zippo’s rechargeable, IP57-rated hand warmer offers three heat settings and up to six hours of runtime. It can also serve as a 24-lumen flashlight or a 5,200 mAh power bank in a pinch, though, unlike most warmers, it’s only sold as a single unit.
Where to Buy:
- If you own an older iPhone with a Lightning port, you can grab InfinityLab’s InstantGo 10,000 Power Bank for just $41.93 (about $28 off) at REI. The portable battery features a 10,000mAh capacity and a built-in Lightning cable, making it a solid all-in-one option for days when you won’t be near an outlet. It also supports passthrough charging, allowing you to charge your phone and the power bank simultaneously.
-
From latency to instant: Modernizing GitHub Issues navigation performance
When you’re working through a backlog—opening an issue, jumping to a linked thread, then back to the list—latency isn’t just a metric. It’s a context switch. Even small delays add up, and they hit hardest at the exact moments developers are trying to stay in flow. It’s not that GitHub Issues was “slow” in isolation; it’s that too many navigations still paid the cost of redundant data fetching, breaking flow again and again.
Earlier this year, we set out to fix that—not by chasing marginal backend wins, but by changing how issue pages load end-to-end. Our approach was to shift work to the client and optimize perceived latency: render instantly from locally available data, then revalidate in the background. To make that work, we built a client-side caching layer backed by IndexedDB, added a preheating strategy to improve cache hit rates without spamming requests, and introduced a service worker so cached data remains usable even on hard navigations.
In this post, we’ll walk through how the system works and what changed in practice. We’ll cover the metric we optimized for; the caching and preheating architecture; how the service worker speeds up navigation paths that used to be slow; and the results across real-world usage. We’ll also dig into the tradeoffs—because this approach isn’t free—and what still needs to happen to make “fast” the default across every path into Issues. If you’re building a data-heavy web app, these patterns are directly transferable: you can apply the same model to reduce perceived latency in your own system without waiting for a full rewrite.
The speed of thought: Web performance in 2026
In 2026, “fast enough” is not a competitive bar. For developer tools, latency is product quality. When someone is triaging multiple issues, reviewing a feature request or reporting a bug, every avoidable wait breaks flow.
Modern local-first tools and aggressively optimized clients have moved the standard from “loads in a second” to “feels instant.” In this world, users do not benchmark us against old web apps. They benchmark us against the fastest experience they have ever had every day.
GitHub Issues is not a small surface area. Every week millions of people around the world rely on Issues to keep their codebase running smoothly. As Issues also becomes the planning layer for AI-assisted work, perceived performance becomes even more critical: if the loop between intent and feedback is slow, the entire system feels slow.
We heard the same problems from both internal teams and the community: Issues felt too heavy compared to tools built with speed as a first principle. The bottleneck was not feature depth or correctness. It was architecture and request lifecycle. Too many common paths still paid the full cost of server rendering, network fetches, and client boot, even when data had effectively been seen before.
Our Issues Performance team’s job was to close that gap. The objective was straightforward and technical: redesign data flow and navigation behavior so the product feels instant by default.
Before changing architecture, we needed to align on what “fast” means in user terms and how to measure it. Generic page metrics are useful, but they are not sufficient for a complex product surface like Issues.
We use HPC (Highest Priority Content), an internal metric closely aligned with Web Vitals LCP, to measure when the primary content (the content users care about) on the page is first rendered. Like LCP, this is anchored to a single HTML element selected by the browser, which on issue pages is most often the issue title or the issue body. If that element is rendered quickly, the experience feels responsive even if non-critical page regions are still loading.
Operationally, we bucket navigations using HPC thresholds:
- Instant: HPC < 200 ms
- Fast: HPC < 1000 ms
- Slow: HPC >= 1000 ms
These thresholds give us a practical model for user-perceived speed, not just raw backend latency. The <200 ms bucket maps to interactions that feel immediate in real workflows, while the <1000 ms bucket captures experiences that are still acceptable but no longer invisible to users.
This is also the point at which our measurement philosophy evolved. Historically, we dedicated significant effort to tracking the p90 and p99 of the HPC and minimizing the worst tail of the distribution. While this work remains important, it does not inherently ensure that the product feels fast for the majority of users. It is possible to enhance the p99 of the HPC while still leaving the median experience feeling sluggish.
For this initiative, we shifted focus toward distribution quality: how many navigations land in our fast and instant buckets across the whole population? The goal is not just fewer terrible outliers. It’s to make speed the default path for the majority of sessions.
The baseline: Navigation mix before we changed anything
Before implementing optimizations, we needed a clear model of how users were actually reaching
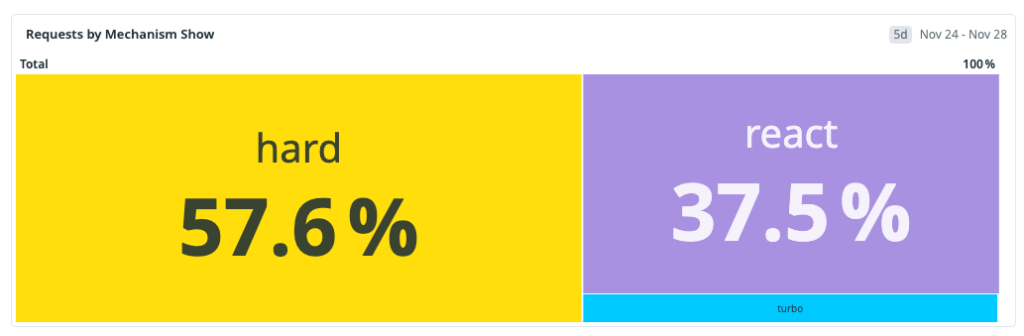
issues#show(the route for viewing an issue). Treating all navigations as one class of traffic would hide the real bottlenecks.We identified three primary navigation types:
- Hard navigation: a full browser load (cold start or refresh) where we pay the full cost of network, server rendering, asset loading, JavaScript boot and React hydration.
- Turbo navigation: a Rails Turbo transition that updates targeted page regions without a full reload. It avoids some hard-navigation overhead but still depends heavily on server-rendered responses.
- Soft navigation (React): a client-side transition inside the existing React runtime, where we can often avoid full page bootstrap costs.
Our measured distribution at the start of the workstream was:
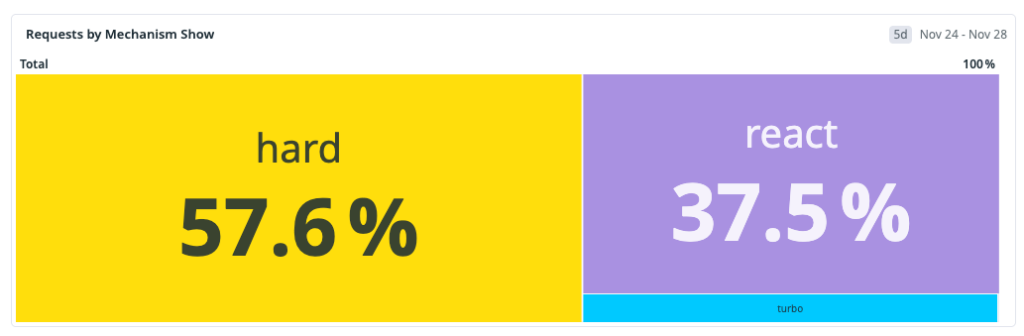
That distribution made one thing obvious: the dominant path was also the slowest. Any strategy focused only on React soft navigations could improve part of the experience, but it could not move overall perceived performance enough on its own.
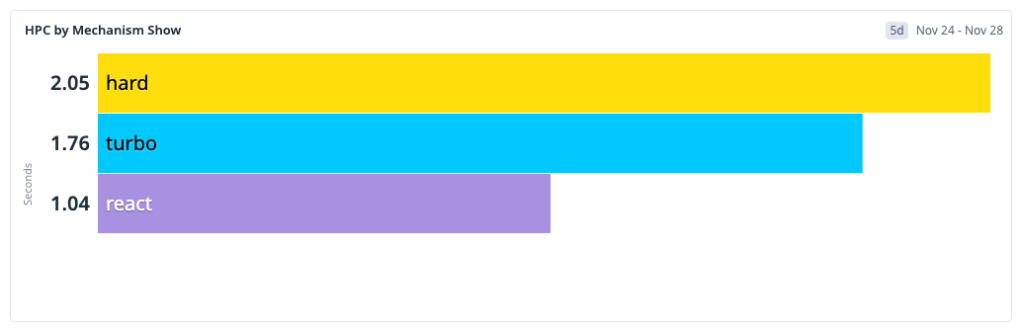
This baseline shaped our next architecture decisions: improve the fast paths and reduce the hard-navigation penalty, because that’s where most users were seeing the most latency.
One thing to note: GitHub is still in the middle of moving from Rails-rendered pages to a React frontend. During that transition, many user journeys cross the Rails/React boundary. When that happens—for example, navigating from a Rails page into Issues—the browser often has to do a full hard navigation and cold boot. That boundary crossing is a big reason hard navigations made up the largest share of our baseline.
We expect that share of hard navigations to decrease over time as more surfaces become React-native. But we could not wait for platform migration alone to solve our problem. We started by optimizing React soft navigations first, where we had immediate architectural leverage and could ship improvements quickly.
Once we aligned on the target, our strategy became clear: build a local-first application model with stale-while-revalidate. That means rendering immediately from locally available data to minimize user-visible latency, then asynchronously revalidating against the server and reconciling the UI if newer data exists.
Step 1: Client-side caching with IndexedDB
We started where we had the most leverage and where we want to move most traffic in the future: React soft navigations. In this path, the runtime is already alive, so the dominant cost is usually data fetch latency, not application boot. If we could remove network from repeated visits, we could move a large slice of traffic into the instant bucket.
Our pre-workstream analysis showed a strong repeated-access pattern: users reopen the same issues frequently during triage and collaboration loops. Based on that behavior, we estimated a potential cache-hit ratio of roughly 30% for
issues#showand used that as the initial viability threshold.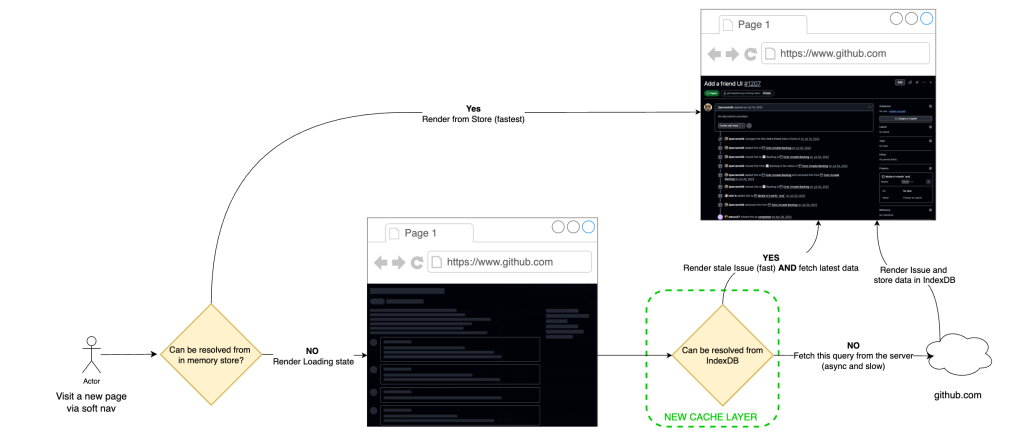
The implementation was to extend our current in-memory store with a persistent client cache in IndexedDB.
Why we chose IndexedDB for this layer:
- Durable browser storage that survives tab closes and browser restarts, unlike memory-only stores.
- Indexed object-store model, which gives efficient key-based lookups for issue query payloads.
- Larger practical quota than localStorage, making it appropriate for real working sets.
On top of that storage layer, we implemented stale-while-revalidate semantics:
- Read path: on soft navigation, attempt to hydrate from local cache first and render immediately.
- Revalidation path: issue a background network request for freshness and reconcile the in-memory store if data changed.
- Failure behavior: when network is degraded, users still get a usable page from cache, with freshness reconciled once connectivity recovers, introducing a new graceful-degradation model.
The architectural point is that this is not “cache or correctness.” It is latency-first rendering with asynchronous consistency checks on the same navigation.
Initial production results validated the model. After broad rollout to all users, approximately 22% of React navigations became instant—up from 4% pre-launch—representing about 15% of total request volume. Observed cache-hit ratio landed around one-third (~33%), which was consistent with the earlier revisit analysis.
The main tradeoff is controlled staleness. We measured server/cache divergence at about 4.7% and treated that as an explicit operating envelope: acceptable for the perceived speed gains on soft navigations, with safeguards to limit user-visible inconsistency.
Moving the needle on cache-hit ratios
Caching is only as good as its cache-hit ratio. The IndexedDB-backed SWR (Stale-While-Revalidate) layer gave us a strong first step, but a one-third hit rate also exposed the next limitation: most navigations still arrived before the data did.
The naive answer was obvious: prefetch every likely next issue as early as possible. We explored that direction and quickly ran into the real constraint, which was not implementation complexity but capacity. On high-fanout surfaces such as issue lists, dashboards, and projects, eager prefetching amplifies request volume, creates N+1-style access patterns and pushes unnecessary compute onto the system for pages a user may never open.
So we changed the objective. Instead of trying to make prefetched data always fresh, we optimized for a cheaper and more scalable condition: make sure some usable data is already local by the time the user clicks.
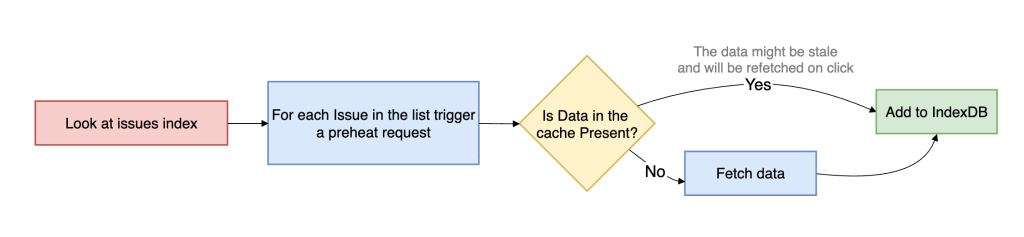
That is preheating. Preheating proactively walks high-intent issue references and prepares cache entries ahead of navigation, but it only hits the network when the issue is not already present in the client cache. If usable data already exists, preheating stops. This makes it fundamentally different from traditional preloading. It is cache-population logic, not freshness-enforcement logic.
This is an explicit tradeoff between freshness and capacity usage. We are willing to serve data that may be slightly stale if that allows the navigation itself to complete near instantaneous, because once the user opens the issue, we can still revalidate in the background and converge to the latest server state.
To support that model efficiently, we introduced an in-memory cache version in front of IndexedDB. IndexedDB gives persistence across tabs and sessions, but it is still asynchronous and therefore not free on the critical path. The in-memory layer sits between the active in-memory store and persistent storage, allowing hot issue payloads to be served synchronously without paying even the IndexedDB read cost. In practice, this removes another async boundary from soft navigation and materially increases the probability of rendering directly from memory.
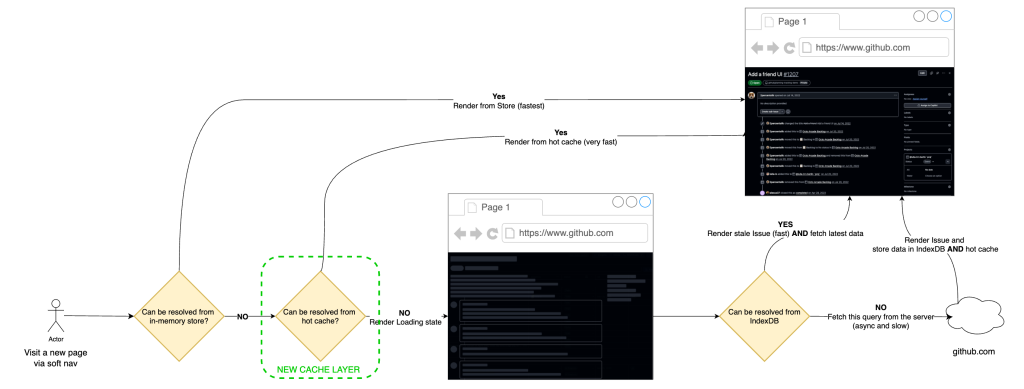
Operationally, preheating is triggered from high-intent surfaces such as issue lists, dashboards, projects, and dependency views. Requests run on low-priority workers, are strictly rate-limited and are guarded by circuit breakers, so the mechanism backs off under pressure. User-initiated work always takes precedence over speculative fetches, allowing us to avoid the noisy-neighbor problem and keep the system stable while still improving cache-hit ratios for real user navigations.
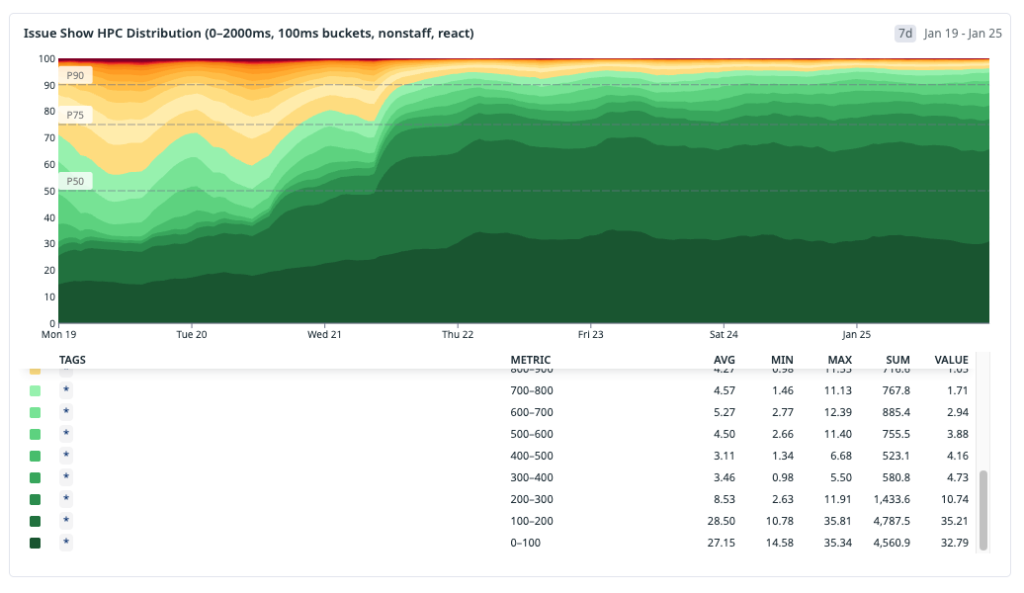
The result was a large shift in distribution. After rolling out preheating broadly, instant navigations for
issues#showincreased to roughly 30% overall. For React navigations specifically, up to ~70% became instant. Cache-hit ratio rose to roughly 96%.That tradeoff was acceptable. We spent a small amount of controlled background capacity to move a large percentage of real user navigations out of the network-bound path.
Expanding the fast path: Optimizing turbo and hard navigations
We were happy with the React navigation gains, but soft navigations aren’t the whole story. Even as more of GitHub moves from Rails to React, hard navigations will always exist—refreshes, new tabs, direct URLs, and inbound links. Those cold starts still matter, so we wanted cached data to help there too.
The mechanism we chose was a service worker.
A service worker is a browser-managed script that runs outside the page itself and can intercept network requests before they reach the server. Conceptually, it sits between the browser and the origin as a programmable middleman. That makes it one of the few web platform primitives that can influence hard navigations without requiring the page’s JavaScript runtime to already be active.
For
issues#show, our service worker extends the same local-first model we built for React navigations. When the browser starts a navigation request for an issue page, the service worker intercepts it and checks whether the issue data is already available in local cache. If it is, the worker annotates the outgoing request with a specific header that tells the server it can skip a substantial amount of work.
When the service worker detects a cache hit, it signals to the server via a request header. From there, the navigation splits into two paths:
- Cache hit path: return a thin HTML shell (layout + minimal markup + JS), and let React render from the locally cached issue payload.
- Cache miss path: return the normal response (server loads data and SSRs the page).
This is a strict optimization: if the cache is cold, stale, or the service worker isn’t available, behavior falls back to the standard server-rendered path.
This had an especially strong effect on Turbo navigations, because Turbo paths are still heavily constrained by server response time. Once the service worker can signal that issue data is already present, the server spends much less time computing the application fragment, and Turbo benefits almost immediately from that reduction in backend work.
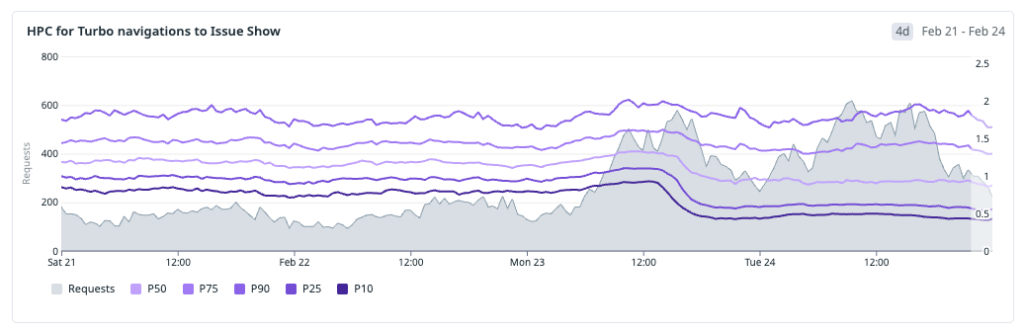
Hard-navigation gains are real, but they are less immediately visible than Turbo gains: on cache-hit hard navigations, so we trade SSR time for client-side rendering. The critical path now becomes JavaScript download and execution.
To reduce that cost, we split code by route using
React.lazyand dynamic route preloading, so only the code required for the current route is fetched up front. We apply the same principle at the component level, loading only what’s necessary for the initial view and deferring non-critical modules. For example, we only fetch the issue editor bundle when a user enters edit mode, and use intent-based prefetching (like hover) to hide that latency without bloating the initial bundle.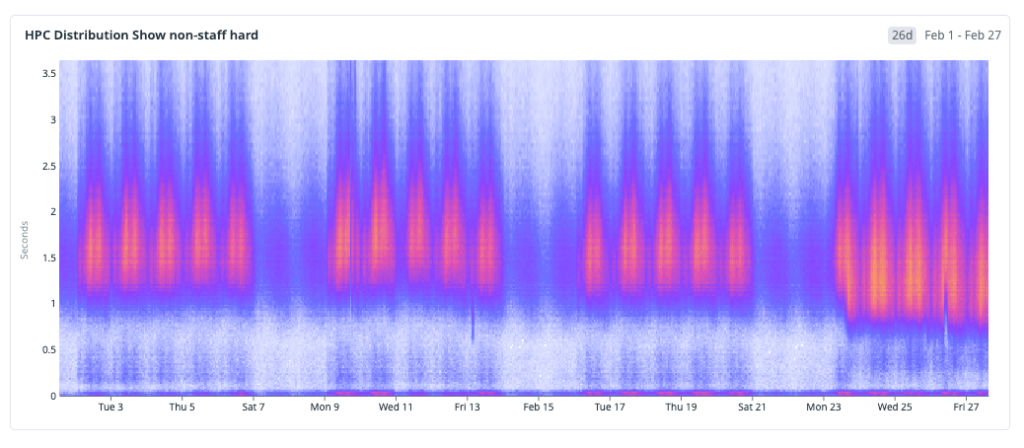
The results
After deploying these changes, we wanted to step back and look at the cumulative impact. We analyzed the HPC metric across the entire rollout period—from the initial IndexedDB cache through preheating, in-memory layering, and the service worker—and the trend is clear and sustained: the distribution is shifting toward fast.
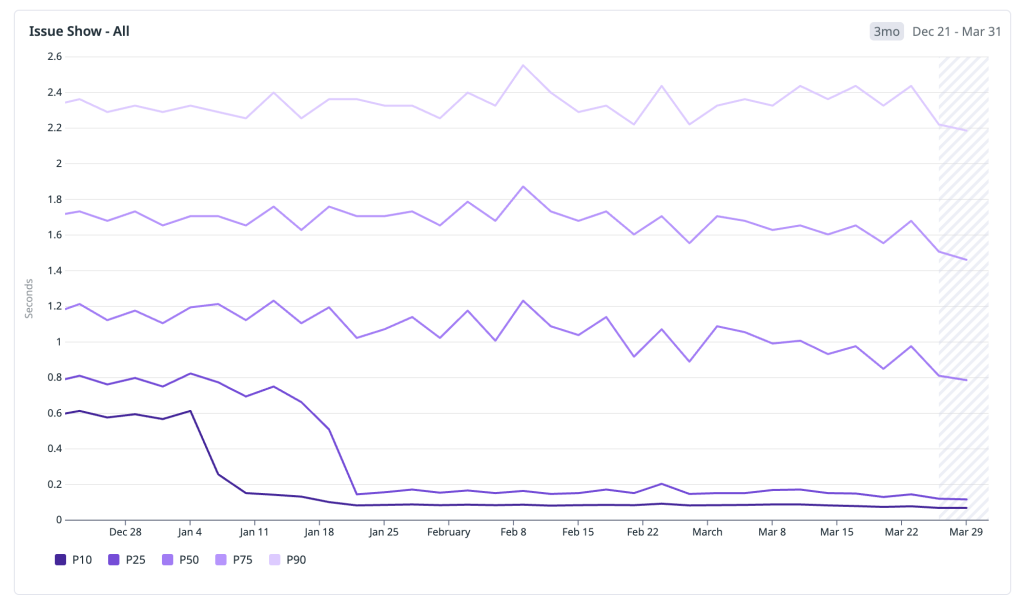
Rather than cherry-pick a single good week, we looked at the full window to share some concrete wins from recent months. Below are the HPC percentiles across all issues#show traffic:
- P10: ~600 ms → 70 ms — the fastest navigations moved firmly into the instant bucket, well below 200 ms.
- P25: ~800 ms → 120 ms — a quarter of all navigations now complete in under 120 ms, down from nearly a full second.
- P50: ~1,200 ms → 700 ms — the median experience crossed below the one-second threshold, moving from the slow bucket into fast.
- P75: 1,800 ms → 1,400 ms — the upper quartile dropped by over 400 ms, shrinking the long tail of perceptible latency.
- P90: 2,400 ms → 2,100 ms — even the slowest navigations improved, though this tail remains the clearest signal of where further work is needed.
The pattern that stands out is the outsized improvement in the lower percentiles. P10 and P25 compressed dramatically because cached and preheated navigations now dominate that part of the distribution. The median improved meaningfully but is still shaped by cold-start traffic. And the upper tail, while better, reflects the hard-navigation paths where JavaScript boot and client rendering are now the bottleneck—exactly the area we are targeting next.
Numbers tell the optimization story, but what ultimately matters is the user impact. The video below shows what these changes feel like in practice—navigating between issues at full speed in a real session:
The work ahead
GitHub Issues is faster today than it has ever been. Across soft navigations, preheated paths, and service-worker-accelerated flows, we have materially changed the distribution of user-perceived latency and moved a much larger share of traffic into the instant bucket.
At the same time, we are not done. Cold starts that rely on SSR are still a real hurdle, especially when client boot and JavaScript execution become the dominant cost after server work is reduced.
The next phase is about moving bigger rocks. We are planning targeted rewrites of parts of our backend stack optimized explicitly for low-latency delivery and are investing in a modern UI delivery layer closer to the edge to reduce round trips and improve response time further.
Performance remains a continuous systems investment, not a one-time project. The architecture is improving, the bottlenecks are changing, and we will keep iterating until fast is the default experience across all navigation paths.
Check out the Quickstart guide for GitHub Issues >
The post From latency to instant: Modernizing GitHub Issues navigation performance appeared first on The GitHub Blog.
-
GitHub availability report: April 2026
In April, we experienced 10 incidents that resulted in degraded performance across GitHub services.
To increase transparency, at the end of April, we released a blog post covering major incidents on April 23 and April 27. We have also taken steps to bring more detail to the GitHub status page.
Thank you for your patience as we work through near-term and long-term investments we’re making.
April 01 15:02 UTC (lasting 8 hours and 43 minutes)
On April 1, 2026, between 14:40 and 17:00 UTC, GitHub’s code search service was fully unavailable; 100% of search queries failed. Service was restored in a degraded state by 17:00 UTC with temporarily stale results, and fully recovered with current data by 23:45 UTC.
During the 2 hour and 20 minute period of full unavailability, 100% of code search requests failed. After initial recovery at 17:00 UTC, search returned results, but they did not reflect repository changes made after approximately 07:00 UTC that day. Full indexing caught up by 23:45 UTC.
During a routine infrastructure upgrade to the messaging system supporting code search, an automated change was applied too aggressively, causing a coordination failure between internal services. This halted search indexing, and search results began going stale. While the team worked to recover the messaging infrastructure, an unintended service deployment cleared internal routing state, escalating the staleness issue into a complete outage.
We restored the messaging infrastructure through a controlled restart, reestablishing coordination between services. We then reset the search index to a point in time before the disruption. No repository data was lost—the search index is a secondary index derived from Git repositories, which were completely unaffected. Once re-indexing completed, all search results reflected the current state of repositories.
We are adding more gradual upgrades with better health checks, so problems are caught before they cascade, deployment safeguards to prevent unintended changes during active incidents, faster recovery tooling to reduce time to restore service and better traffic isolation to prevent cascading impact from unexpected traffic spikes during outages.
April 01 16:06 UTC (lasting 4 minutes)
On April 1, 2026, between 15:34 UTC and 16:02 UTC, our audit log service lost connectivity to its backing data store due to a failed credential rotation. During this 28-minute window, audit log history was unavailable via both the API and web UI. This resulted in 5xx errors for 4,297 API actors and 127 github.com users. Additionally, events created during this window were delayed by up to 29 minutes in github.com and event streaming. No audit log events were lost; all audit log events were ultimately written and streamed successfully. Customers using GitHub Enterprise Cloud with data residency were not impacted by this incident.
We were alerted to the infrastructure failure at 15:40 UTC—six minutes after onset—and resolved the issue by recycling the affected environment, restoring full service by 16:02 UTC. As a result of the incident, we completed several follow-up actions to reduce the risk of recurrence and improve detection. The team updated and strengthened the credential rotation process to improve resiliency and help prevent similar failures in the future. In parallel, we enhanced our monitoring configuration, including making paging thresholds more sensitive to improve detection speed and operator visibility into similar issues going forward.
April 09 09:50 UTC (lasting 25 minutes) and 16:20 UTC (lasting 4 hours and 16 minutes)
On April 9, 2026, we had two incidents, between 09:05 UTC and 19:05 UTC and between 16:05 UTC and 20:36 UTC, where the Copilot coding agent service was degraded and users experienced significant delays starting new agent sessions. Approximately 84% of new agent session requests were delayed across four separate outage waves, with queue wait times peaking at 54 minutes compared to a normal baseline of 15–40 seconds. On average, the error rate was 83.9% and peaked at 97.5% of requests to the service. Approximately 22,700 workflow creations were delayed or failed during the incident.
This was due to a bug in our rate limiting logic that incorrectly applied a rate limit globally across all users, rather than scoping it to the individual installation that triggered the limit. A contributing factor was a surge in API traffic from a client update that increased requests to an internal endpoint by 3–4x, which accelerated rate limit exhaustion. The second similar incident was also caused due to an internal service exceeding API rate limits, compounded by a caching bug that persisted the rate-limited state beyond the actual rate limit window, causing recurring outage.
Our team detected the issue within 15 minutes and began investigating immediately. We mitigated the incident by disabling the faulty rate limit caching mechanism via feature flag and updating our service to use per-installation credentials for API calls, ensuring rate limits are correctly scoped to individual installations. Service was fully restored by 20:36 UTC. Jobs that were delayed during the incident were queued and processed once service resumed.
We have since added automated monitoring and alerting to detect this failure mode proactively, deployed fixes to reduce unnecessary API traffic through caching improvements, and are continuing work to further isolate rate limit scoping across client types to prevent similar issues in the future.
April 13 19:56 UTC (lasting 39 minutes)
On April 13, 2026, between 18:53 UTC and 20:30 UTC, the GitHub Pages service experienced elevated error rates. On average, the error rate was 10.58% and peaked at 12.77% of requests to the service, resulting in approximately 17.5 million failed requests returning HTTP 500 errors.
This incident was due to an automated DNS management tool erroneously deleting a DNS record for a GitHub Pages backend storage host after its upstream data source intermittently failed to return the record, causing the tool to treat it as stale and remove it. As cached copies of the record expired across our systems, GitHub Pages servers were no longer able to reach the affected storage host, resulting in errors for a portion of requests.
Once the issue was identified, our team quickly traced it to the missing DNS record and re-created it. Service returned to normal by 20:30 UTC, and the incident was fully resolved by 20:35 UTC. We recognize that detection took longer than we would have liked—approximately 53 minutes—due to the gradual nature of the error increase and a gap in our alerting for this type of failure.
We are making three key improvements to prevent similar issues in the future. We are implementing availability-zone-tolerant routing in the GitHub Pages frontend so that an unresolvable backend host triggers failover to healthy hosts rather than returning errors, adding safeguards to prevent automated deletion of DNS records owned by other systems, and improving logging and alerting for DNS resolution failures in the GitHub Pages serving path.
April 16 15:06 UTC (lasting 3 hours and 22 minutes)
On April 16, 2026, between 09:30 UTC and 17:15 UTC, users experienced failures when attempting to connect to GitHub Codespaces via the VS Code editor. During this time, approximately 40% of codespace start operations failed. Users connecting via SSH were not impacted.
The issue was caused by failures in an upstream service that prevented the VS Code Server from being retrieved during codespace startup. The impact was mitigated by implementing a workaround to use an alternative download path when the primary endpoint is degraded. In parallel, we coordinated with the upstream dependency team to address the root cause of the download failure.
We are improving our fallback mechanism to reduce the impact of similar upstream failures in the future and streamlining processes to accelerate deployment of similar changes in the future.
April 20 13:28 UTC (lasting 15 hours and 36 minutes)
On April 20, 2026, between 10:28 UTC and 15:04 UTC, GitHub experienced degraded service for code scanning default setup, code quality, and project boards. Repair of affected project boards additionally lasted until 05:04 UTC on April 21.
During this time, code scanning default setup and code quality analyses were not triggered on newly opened pull requests. Additionally, newly created issues were not appearing on project boards.
The cause was a serialization error that prevented proper triggering of code scanning, code quality analyses, and project board updates.
We identified the issue within ~40 minutes and mitigated the issue by deploying a fix, restoring event publishing for code scanning and code quality. For project boards, an additional code change was deployed to update event consumers, followed by a reindex of affected project items.
We are working to prevent recurrence by strengthening our schema validations and improving monitoring for drops in publishing on critical topics. In addition, we are auditing other parts of our system to ensure no similar limitations exist elsewhere.
April 22 15:35 UTC (lasting 3 hours and 43 minutes)
On April 22, 2026, between 15:16 UTC and 19:18 UTC, users experienced errors when interacting with Copilot Chat on github.com and Copilot Cloud Agent. During this time, users were unable to use Copilot Chat or Copilot Cloud Agent. Copilot Memory (in preview) was not available to Copilot agent sessions during this time.
The issue was caused by an infrastructure configuration change that resulted in connectivity issues with our databases. The team identified the cause and restored connectivity to the database. Copilot Chat and Cloud Agent for github.com were restored by 18:16 UTC. Remaining regional deployments were restored incrementally, with full resolution at 19:18 UTC.
We have taken steps to prevent similar infrastructure changes from causing these kinds of database operations in the future.
April 23 16:12 UTC (lasting 1 hour and 18 minutes)
On April 23, 2026, between 16:03 and 17:30 UTC, users experienced elevated error rates and degraded performance across GitHub Copilot, Webhooks, Git Operations, GitHub Actions, Migrations, and Deployments. Approximately 5–7% of overall traffic was affected during the 1 hour and 27 minute impact window. For Copilot, ~7% of AI model requests failed, ~10% of Copilot cloud agent sessions were affected, and ~9% of Copilot Insights dashboard requests returned errors. For Webhooks, ~0.35% of API requests returned errors at peak, with up to 10% of traffic experiencing elevated latency (>3 seconds). Git Operations averaged 1.25% errors over the incident duration, with a peak of 2.07%. GitHub Actions saw workflow run status updates experienced delays of up to ~8 seconds. For Migrations, 0.88% of active repository migrations failed, and 79% saw elevated durations. Deployments were temporarily blocked during the incident window.
Our DNS infrastructure in one datacenter entered a degraded state and began intermittently failing to resolve service addresses. This caused a cascading impact: services that depend on name resolution to communicate with internal APIs, external providers, and storage systems all experienced errors simultaneously.
The root cause was a recently introduced traffic-balancing mechanism that had been rolled out progressively to support our growth. Under a specific load pattern, this mechanism caused DNS resolvers to begin failing. Existing DNS caching provided partial protection. Services with recently cached entries continued operating normally, which is why overall impact was limited to approximately 5–7% of traffic rather than a complete outage.
After an initial configuration rollback did not resolve the issue, we restarted the affected DNS infrastructure. Services began recovering within minutes, and all returned to normal by 17:30 UTC. No data was lost; all repositories, databases, and workflow data were unaffected.
To prevent incidents like this in the future we are improving our DNS infrastructure resilience to prevent single-datacenter failures from cascading across services, implementing safer rollout and validation with a dedicated environment to test infrastructure changes against production-like traffic, investing in faster automated detection and recovery with self-healing mechanisms for DNS resolution failures and reducing blast radius by reviewing service dependencies on shared infrastructure components.
April 27 16:31 UTC (lasting 6 hours and 15 minutes)
On April 27, 2026, between 16:15 UTC and 22:46 UTC, GitHub search services experienced degraded connectivity due to saturation of the load balancing tier deployed in front of our search infrastructure. This resulted in intermittent failures for services relying on our search data including Issues, Pull Requests, Projects, Repositories, Actions, Package Registry and Dependabot Alerts. The impact was varied by search target, with services seeing up to 65% of searches timing out or returning an error between 16:15 UTC and 18:00 UTC.
We detected the drop in search results through our ongoing monitoring and declared an incident at 16:21 UTC. We tracked the incident as mitigated as of 21:33 UTC and monitored the systems until 22:46 UTC when we declared the incident resolved.
The saturation was caused by a large influx of anonymous distributed scraping traffic that was crafted to avoid our public API rate limits. This scraping traffic made up 30% of the day’s total search traffic, but it was concentrated within a four-hour period. The traffic originated from over 600,000 Unique IP addresses, with matching actor information in all requests. Our existing monitoring did not classify the increased scraping as a risk and this dimension of the incident was only discovered while working to mitigate.
To mitigate, we immediately focused on relieving pressure from the load balancers while simultaneously working on scaling the load balancing tier, blocking the anomalous traffic and applying tuning to the balancers to fully resolve the incident.
Looking ahead, we’ve not only scaled the load balancer tier, but applied optimizations to improve our connection handling and re-use to reduce the possibility that a saturation event like this can re-occur. We’ve also added new monitors and controls within the platform to allow us to restrict anonymous traffic to mitigate the impact to our registered users. We are continuing to strengthen our defenses against this type of large-scale automated abuse.
Follow our status page for real-time updates on status changes and post-incident recaps. To learn more about what we’re working on, check out the engineering section on the GitHub Blog.
The post GitHub availability report: April 2026 appeared first on The GitHub Blog.